Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
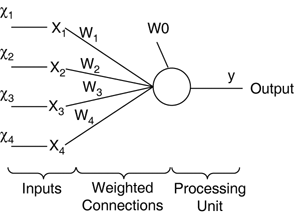
Model OverviewPerceptrons essentially consist in a layer of weights, mapping a set of inputs Figure 17.2. A perceptron with four inputs and a single output.
Multiple outputs The weights are denoted
The choice of data type for the inputs, outputs, and weights has changed over the years, depending on the models and the applications. The options are binary values or continuous numbers. The perceptron initially used binary values (0, 1) for the inputs and outputs, whereas the Adaline allowed inputs to be negative and used continuous outputs. The weights have mostly been continuous (that is, real numbers), although various degrees of precision are used. There is a strong case to use continuous values throughout, as they have many advantages without drawbacks. As for the data type, we'll be using 32-bit floating-point numbers—at the risk of offending some neural network purists. Indeed, 64 bits is a "standard" policy, but in games, this is rarely worth double the memory and computational power; single precision floats perform just fine! We can do more important things to improve the quality of our perceptrons, instead of increasing the precision of the weights (for instance, revise the input/output specification, adjust the training procedure, and so forth). The next few pages rely on mathematics to explain the processing inside perceptrons, but it is kept accessible. (The text around the equations explains them.) The practical approach in the next chapter serves as an ideal complement for this theoretical foundation. |
|
|
Ajax Editor
JavaScript Editor