Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Introduction to OptimizationOptimization techniques lead to the best solution for a problem. An ExampleSuppose, for instance, that there's a way to determine how much damage is inflicted based on where the animat shoots. This is done by a simulation on a case-by-case basis, changing the orientation of the weapon and checking how much health the enemy loses. This corresponds to one single point on the 2D graph. By doing this regularly for many orientations, we could get a relatively smooth curve linking all the points together—assuming there are no errors or noise. This curve represents our best knowledge of a mathematical concept of the problem: a function, which links damage with orientation. We say that damage d is a function of orientation o, for some unknown function f. This is written d = f(o) (see Figure 17.4). Figure 17.4. Samples of damage inflicted based on the orientation, along with the curve modeling the concept.
Now this function is just a concept, and only specific orientations (o1,o2) can be checked. However, we are really interested in this function because it can help the animats perform better! By knowing the orientation that inflicts the most damage, the effectiveness of the behaviors can be improved. This is known as a maximization problem: Find the orientation ô for which the damage is highest:
This equation means that the optimal orientation ô is defined such that (|) for all orientations o ( Brute-Force OptimizationGenerally, the notation used is y = f(x) (similar to the definition of the perceptron). The function is sometimes called an energy function (denoted E), which expresses the energy cost of a particular value of x. This originates mainly from physics backgrounds, where many problems require finding the minimal energy instead. To find the optimal value of x, we could use brute force by checking all its values and finding the corresponding y, as illustrated in Figure 17.5. However, there are two problems: Figure 17.5. Brute-force optimization checking the values of the function at regular intervals. The maximal value is missed.
Instead, more efficient methodologies can be borrowed from mathematics, physics, or even biology. Generally, examples demonstrate optimization based on single continuous numbers. However, it is also possible to optimize vectors (denoted Numeric OptimizationWe can use a wide variety of techniques to solve these problems, including differential calculus, numeric analysis, and stochastic approaches. Most operate as best-guess techniques, which iteratively improve an estimate. Some of these techniques are easy to understand and implement, whereas others rely on a significant knowledge of calculus. In many cases, the simplest approach is often used—and usually proves satisfactory for game development. The following sections review some of the most popular techniques used. The methods described next can be used to find optimal configurations, whether minimal or maximal. The theory is the same in both cases, although existing terminology focused on minimization. This type of problem is generally known as an optimization problem. In some cases, this optimization is constrained, meaning we need to maintain a condition for the parameters (for instance, x or y within some range). However, we'll focus on problems that have no such constraints because they are more common and appropriate for training perceptrons. Steepest DescentThe steepest descent technique uses information about the slope of a function to find a solution x such that f(x) is a global minimum (that is, the absolute lowest point of the curve). Fundamentally, steepest descent is an iterative process; estimates of the current value x are corrected incrementally. We start with the first estimate x0 and continue until the n + 1th prediction xn is good enough. Deciding when to stop the iteration can be done quantitatively by measuring the change in the estimate: |xi+1 – xi | The first guess x0 is generally made randomly. To improve any estimate xi and get a new one xi+1, we take a step Dxi, which is added to the current value (D is pronounced delta—another Greek letter, of course).
The gradient of the function is needed to determine the value of this step. Visually, the gradient corresponds to the slope of the curve of f at xi, as shown in Figure 17.6. It is written Figure 17.6. Successive steepest descent iterations showing the improvement in the estimates until the process converges at the global minimum.
So why is the gradient needed? The assumption is that the slope of the curve can lead toward a lower point, and eventually the lowest one—where the iteration converges. Basically, the gradient of the function a particular point xi is used to adjust the estimate in the appropriate direction to get xi+1.
The second factor h The graphs in Figure 17.7 reveal the importance of the step. Selecting a learning rate that is too large or too small will lead to two different kinds of problems: oscillation and slow convergence, respectively. Both of these are undesirable because they prevent us from finding the optimal value quickly. Figure 17.7. Problems with the learning rate. On the left, slow convergence, and oscillation on the right.
As such, the adjustment of the learning rate h can play an extremely important role in the whole process. What's more, there is no ideal value for every problem; the learning rate must be chosen on a case-by-case basis, depending on the nature of the function. This unfortunately requires time-consuming experimentation, or setting up a script to gather results. Local MinimaThere's another twist in the plot: Minimal values are not always what they seem; some are imposters! Indeed, there are local minima and global ones. A local minimum is the lowest value in its surrounding neighborhood, but there can exist a lower value elsewhere—the global minimum. This is like the Holy Grail for optimization algorithms, and often takes nothing short of a crusade to find (and guarantee this is the right one). Why can't gradient descent realize that this is the local minimum, and keep descending further? The problem is that the two cannot be distinguished. The process will converge in the local minima as well as global minimum, which means successive estimates will be similar (that is, within e of each other), hence triggering the halting condition (see Figure 17.8). We don't know this solution is not the right one until a better one is found. It is just the best we've found so far. Figure 17.8. A more complex function with multiple local minima, but only one global minimum. The process converges in each case.
Generally, functions are even more complex than the ones depicted here (with one or two minima), so things are worse for real problems. Taking into account oscillation problems and slow convergence reveals an even tougher dilemma. Naturally, AI algorithms prefer near-optimal solutions, which explains the need for more powerful and reliable methods. As we'll see, even more elaborate processes have their problems. Adding MomentumThe optimization algorithms need a simple technique to prevent premature convergence and reduce the likelihood of finding local minima. The concept of momentum comes to the rescue. Momentum decreases the likelihood of premature convergence by providing a sense of short-term history when deciding the next step. Essentially, the value of the previous step Dxi-1 is scaled by a (the Greek alpha) and added to the step normally used in steepest descent (opposite to the gradient with learning rate: – h
The key observation leading to this approach is that the steps taken from iteration to iteration can be extremely erratic. This is caused by the gradients changing often, especially when the steps are large or the function is complex. The addition of momentum can help smooth things out and use previous trends to help choose the next step (see Figure 17.9). Figure 17.9. Using momentum to overcome local minima and smooth out the steps to prevent oscillation in areas with high variations.
Metaphorically, a process with momentum can be understood as a ball rolling around a landscape. The speed of the ball will build up on the way down toward the valley, and its physical momentum will carry it quite far up the other side. If this peak is relatively low (local minimum), the momentum will push the ball straight over into a larger valley (global minimum). This can lead to better solutions being discovered. Simulated AnnealingSimulated annealing is another simple and relatively efficient solution to the optimization problem. Unlike the previous methods, this is not gradient based, although in practice, information about the slope can be used to assist the process. Simulated annealing is modeled on the physical process that happens to the atomic structure of a metal while it cools down, as it settles into a configuration that minimizes energy. This process is known as annealing, and can be simulated to solve optimization problems—hence the name simulated annealing. Conceptually, the method is based on chaos. No matter how much we know about the function already, the estimate of the next iteration is always a guess (the global minima is unknown). So why not voluntarily introduce a bit of randomness into the process to get around the problems of selecting the step's value? In simulated annealing, this is done by a generation mechanism, which stochastically picks a new estimate in the neighborhood of the current estimate. The generation mechanism depends on the type of variables being optimized; generating neighboring estimates requires knowledge of the representation. For real numbers, this can be done with random offsetting (that is, addition of a small value). Just like for the metals cooling, simulated annealing is based on the concept of temperature. If the new estimate is better, it is always used rather than the current one. On the other hand, when the new estimate is worse, we decide whether to accept it based on the temperature. Temperature is a value denoted T that controls the probability p of accepting a positive change Df in the function f when a new estimate is made:
This equation is known as a Boltzmann distribution. k is a constant used to scale the temperature. The procedure for decreasing the temperature is known as a cooling schedule. In practice, temperature starts very high and decreases in stages. The theory behind simulated annealing is that the optimization will settle into a global minimum as the temperature decreases (see Figure 17.10). Figure 17.10. Optimization in a 2D plane using simulated annealing. Large steps are taken at first, and then smaller ones as the temperature cools.
This method has variable benefits; in some cases, it can work nicely to optimize functions, but in others, it can be extremely slow because of its stochastic nature. One of the major criticisms is that simulated annealing is just greedy hill-climbing when the probability p = 0. (That is, better neighbors are always selected.) This reveals the importance of the cooling schedule, and explains why simulated annealing can be such a dark art. |
|
|
Ajax Editor
JavaScript Editor



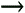
 e. The Greek epsilon e is a small quantity used as a threshold to compare the difference in successive estimates. The process is said to have
e. The Greek epsilon e is a small quantity used as a threshold to compare the difference in successive estimates. The process is said to have