Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
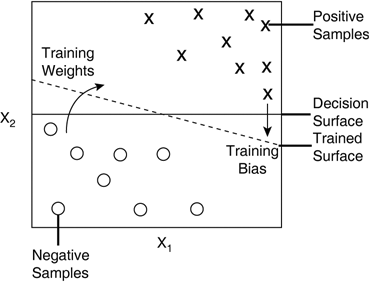
Graphical InterpretationA concrete example will give us a better understanding of what's going on internally. A linear function in 2D is just a line. In fact, the equation of the perceptron has the same format as a line (a+bx1+cx2). When the weights are multiplied with the input, this is reminiscent of a dot product. In 2D, the dot product enables us to determine the "signed distance" to the line; taking the sign of the result determines the side of the line, and the absolute value represents the distance (see Figure 17.12). Figure 17.12. Visualization of the perceptron's decision surface on a 2D example.
What does it mean for function prediction? The output of perceptrons is the signed distance from the input to the line. If a binary output is used, the perceptron indicates on which side of the line the input sample lies. The training process is all about finding the right position for the line in space. To achieve this, the delta rule adjusts the weight coefficients of the lines (that is, orientation). The bias is necessary to change the position relative to the origin. If all the data can be plotted in two dimensions, it is possible to visually find a solution; this is the line that minimizes the errors in classification. In 2D, understanding the perceptron as a line is quite straightforward. In 3D, this corresponds to a plane, separating the patterns in a volume. For n dimensions, this theory generalizes to a "hyperplane." It can be difficult to imagine any more than three dimensions, but the process is just as simple. |
|
|
Ajax Editor
JavaScript Editor