Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
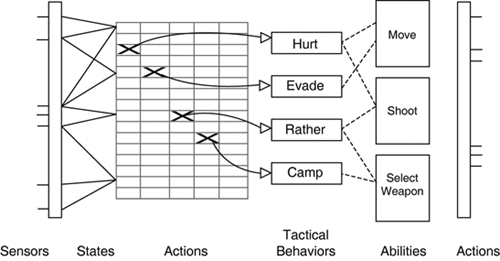
Decomposition by ControlReinforcement learning algorithms are generic tools for finding the mapping between states and actions. They can be applied to learning deathmatch strategies by associating situations with the right behavior. The entire problem could be handled using a single table storing a probabilistic policy, indicating the estimated return for each state/action. Each type of RL algorithm is capable of dealing with this problem successfully. One major problem with having a large number of states and actions is that the learning happens more slowly. Additional iterations are required to find a suitable policy. As such, splitting up the problem is advantageous from the point of view of computation and memory consumption. Furthermore, the use of parallel RL means that multiple actions may be dealt with. All the algorithms discussed in Chapter 46, "Learning Reactive Strategies" are capable of selecting only one action and distributing the reward accordingly. Handling multiple parallel actions and splitting the reward is an active problem in RL research. To get around this issue and deal with tactics made of multiple components, the system requires the use of default behaviors (as discussed in Chapter 45, "Implementing Tactical Intelligence") that are called upon by the RL algorithm—as shown in Figure 47.1. Figure 47.1. A single mapping from state to action used to select the appropriate tactical behavior.
Splitting up the problem allows the RL algorithms to tackle each component of the behaviors separately, which inserts more flexibility into the design. Any combination of capabilities may form tactical behaviors, and the AI will adapt to find the most suitable approach. This is depicted in Figure 47.2. Figure 47.2. Multiple RL algorithms deal with components of tactical behaviors, each corresponding to specific outputs.
In this chapter, we assume the problem is split up into components. Each component controls a different part of the animat, so the decomposition is based on the outputs. It is worthwhile noting that memory consumption may be similar in both cases, because the state space could be designed identically in both cases. The advantages lie in simplifying the reinforcement problem itself. As well as decomposing the behaviors into separate capabilities, it's also possible to split the reward signal, distributing it to the components as appropriate. For example, the reward associated with collecting items is sent to the gathering component, and the reward for enemy damage is sent to the shooting component. This is known as modular reward, in contrast with holistic reward signals (which include all forms of feedback together). The major advantage of modular reward signals is that the feedback is highly accurate and relevant to the task at hand, reducing the amount of noise present. The next sections discuss the different learning components individually:
Each is handled using different RL algorithms. |
|
|
Ajax Editor
JavaScript Editor