Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Tactical Thinking ExplainedA formal definition of tactic is the sequence of operations designed to achieve a goal. Thus, a tactic consists of three elements:
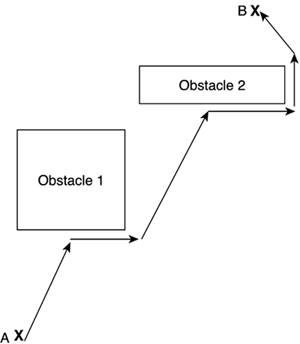
Human brains are very well suited for tactic creation. Consciousness informs us of our current state, the goals are set by our internal needs, and our brains create (and modify on the fly) pretty good plans. Machines, on the other hand, are not designed for tactics. They are much better at numerical computations than they are at these kinds of cognitive processes. Proof of this difference is the speed at which a good sorting algorithm was evolved (about 30 years ago). Playing chess, which involves tactics, has only recently been completely mastered, and even today the methods are quite brute force, radically different from what a brain would do. Machine tactics are complex for a variety of reasons. As an example, take a bird's eye view of a battlefield, as seen in popular games such as Age of Empires. It is no problem for a computer to perform a variety of tests, such as computing distances between enemies, making sure they do not overlap, and so on. But a question like "Who is winning the battle?" is a completely different business. Computers do not know what "winning" means. It's a highly sophisticated concept and definitely not the kind of idea you can represent easily with ones and zeros. Any human being flying over a battlefield would recognize at first sight which side is actually winning, but computers have a hard time coping with this kind of query. Thus, we must begin by creating specific data structures that allow us to ask meaningful questions about the status of the system, so we can build plans based on that status. Another problem derived from machine tactics is making the actual plan. Machines are good at computing plans, but creating one that actually looks human is very complex. As you will soon see, many tactical algorithms have an undesirable side effect. They are too perfect, and thus can frustrate the player in the long run. Besides, they can kill realism in a game. Players will detect an unnatural behavior pattern, and the sense of immersion will be destroyed. We will now study several classic problems, which we can broadly classify into three large groups: learning to move intelligently in a scenario (path finding), learning to analyze the scenario (its geometry, enemies, and so on), and learning to create a meaningful plan in terms of selecting the right actions to achieve our goals. Path FindingIn the previous chapter, we learned how to chase a moving target. We assumed no obstacles were around, and by doing so, calculations were greatly simplified. Now, let's make things more interesting by assuming there are a few existing obstacles. The more obstacles, the more we need to plan the sequence of moves we will use to reach our destination. In fact, as path finding complexity increases, we will reach a point where most animals, man included, would get lost and be unable to succeed in finding an adequate path through the obstacles. Just think about how easy it is to get lost in a city you don't know. Clearly, some analysis beyond basic animal capabilities is required, and that is what this section is all about—finding paths between two endpoints in a world full of obstacles. This problem has been studied thoroughly in both academia and in the games industry, and many good solutions exist. It belongs to the search field of AI: Given initial and end states (represented by the two endpoints), find a sequence of transitions (movements) that allows us to go from one state to the other efficiently. Some of the proposed algorithms will even be optimal, computing the perfect path between two endpoints. But these solutions will often look too perfect and unnatural, because a living entity rarely uses the optimal solution. So let's start with the simplest approaches and refine them to more involved solutions. Path finding algorithms can be divided in two broad categories: local and global. Local approaches try to find a path to a destination by analyzing the surroundings of the current position only. We know in which direction we want to go, and we try to perform the best move by studying our local neighborhood. Global algorithms, on the other hand, analyze the area as a whole and trace the best path using all the information, not only the surroundings. As a side effect, local algorithms are computed online on a frame-by-frame basis, whereas global approaches are usually precomputed in a single shot and then executed. A person visiting a city for the first time would use a local path finding algorithm, trying to determine from his surroundings which is the way to a certain location. Now, give that same visitor a map, and he will be using a global algorithm. He will be able to study the path as a whole and trace an efficient path beforehand. Keep this distinction in mind as you choose which path finding approach you implement. Are your AI entities well informed about the structure of the game world (and can we assume they have a map), or should they use more trial-and-error, which is realistic but nonoptimal? Strategy games have usually chosen global algorithms (such as the popular A*, which we will study later in its own section), whereas action games tend to prefer local approaches. Crash and TurnThe first algorithm we will explore is a local method that quite closely resembles what a simple animal would try to do. Let's start at point A and try to find a way to point B. Logically, we would try to move in a straight line as long as we can. Once we reach an obstacle, we would choose one of the two sides (left or right) and try to go around it using the left- or right-hand rule—follow the object parallel to its sides until we have open line of sight of the destination again, and thus can return to the straight line of advance. The algorithm can thus be formalized as follows: while we have not reached our destination if we can advance in a straight line to the destination point, do so else select one direction (left or right) using one of several heuristics advance in the said direction keeping your left/right hand touching the obstacle's We can see this algorithm in action in Figure 8.1. Figure 8.1. The crash and turn path finding algorithm.
All we need to define is which heuristic we will use to decide which side we will use to go around the obstacle. Two possibilities are
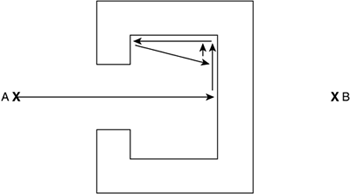
Crash and turn always finds a way from origin to destination if we can guarantee that obstacles are all convex and not connected (two connected convex obstacles could form a concave one). The path is seldom optimal, but will look fine, especially if you are modeling wandering behaviors that do not need to be efficient in the first place. The algorithm is quite lightweight and thus can be implemented with very low CPU impact. As you can imagine, the algorithm has some problems dealing with concave obstacles. We will get stuck in C-shaped areas in an infinite loop, because we won't be able get around the obstacle once we get inside. This situation is clearly depicted in Figure 8.2 Figure 8.2. Stuck trajectory in crash and turn.
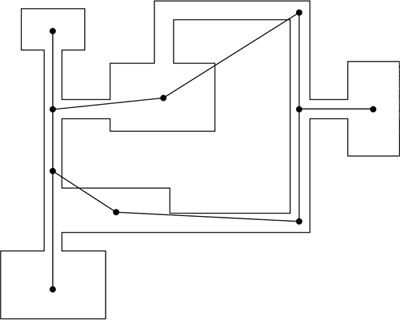
There are some improvements to the original algorithm, but none of them solves the problem completely. In fact, the problem arises from the fact that the algorithm computes the best path based on partial data, and that always incorporates errors into the solution. Dijkstra's AlgorithmThis algorithm, named after its inventor, E. W. Dijkstra, finds optimal paths in those cases where we can describe the geometry of the game world as a set of vertices with weighted connections between them being used to express distances. Take, for example, a level from a first-person shooter as shown in Figure 8.3. To the right you can see the same level represented in terms of vertices (rooms) and edges that are labeled with the distance from one room to another. This kind of data structure, often called a weighted graph, is what Dijkstra's algorithm starts with, so it shouldn't be surprising that this algorithm has been very popular in first-person shooter AI programming. Dijkstra's algorithm is also called a "single source, shortest paths" algorithm, because it does not compute the path between two endpoints, but rather the optimal paths from one source node to all other nodes. The algorithm is very compact and elegant, but quite complex. We will now review it thoroughly, so you can fully understand this cornerstone of path finding programming. Figure 8.3. Top-down view of a game level and associated graph.
The explanation for Dijkstra's algorithm starts with a graph G=(V,E), with V vertices and E edges, and a node s, which is the source. It also has a weight matrix W, which is used to store the weights of the different edges. Starting from the source, we explore the graph using the edges, choosing the lightest weight ones first. For the first step, only the edges from the source can be expanded. But as we move forward, other nodes will have been visited already, and the newly expanded edge will be the one from all the vertices in the visited set that offers the lowest cost. Every time we visit a new node, we store an estimate of the distance between that node and the source. For the first iteration, the estimate is just the weight of the edge we have expanded. Later, as new edges are added to the visited nodes list, the distance can always be broken down into two components: the weight of the edge we just expanded and the best distance estimate of an already visited node. Sometimes, the expansion process will find a way to reach an already visited node using an alternative, lower-cost route. Then, we will override the old path and store the new way of reaching the node. This progressive optimization behavior is called node relaxation, and it plays a crucial role in the implementation of Dijkstra's algorithm. Let's now focus on the algorithm. To begin with, we use two sets. One set contains the nodes that have not been visited (the Pending set), and the other holds the nodes that have already been explored (the Visited set). For efficiency reasons, the Pending set is usually implemented as a priority queue. Additionally, we need two numeric arrays. One array stores the best distance estimate to each node, and the other stores, for each node, its predecessor in the expansion process. If we expand node five, and then we expand node nine, the predecessor of nine is five. The first step of the algorithm initializes this data structure, so we can later loop and compute the shortest paths. The initialization is pretty straightforward, as shown in this subroutine: initialise_single_source( graph g, vertex s) for each vertex v in Vertices( g ) distance[v]=infinity; previous[v]=0; end for distance[s]=0; The second step consists of the relaxation routine. In graph theory, relaxation is the process of iteratively updating a value by looking at its immediate neighbors. In this case, we are updating the cost of the path. Thus, Dijkstra's relaxation routine works by comparing the cost of the already computed path to a vertex with a newer variant. If the new path is less costly, we will substitute the old path for the new one and update the distance and previous lists accordingly. To keep the main algorithm clean and elegant, here is a subroutine that computes the relaxation step given two nodes and a weight matrix: relax(vertex u, vertex v, weights w) if (distance[v] > distance[u] + w(u,v)) distance[v]=distance[u]+w(u,v); previous[v]=u; end if The w structure stores the weights of all edges in the graph. It is nothing but a 2D array of integers or floats. The value stored at w[i][j] is the weight of the edge from vertex i to vertex j. For unconnected vertices, w[i][j] equals infinity. Here is the complete source code for Dijkstra's algorithm in all its glory, making reference to both the initialization and relaxation functions previously provided. Notice how we pass the graph, the weight matrix that specifies the lengths of the edges, and the source vertex that starts the whole process:
dijkstra(graph g, weights w, vertex s)
initialize_single_source(G,s);
Visited=empty set;
Pending=set of all vertexes;
while Pending is not an empty set
u=Extract-Min(Pending);
Visited=Visited + u;
for each vertex v which is a neighbour of u
relax(u,v,w);
end for
end while
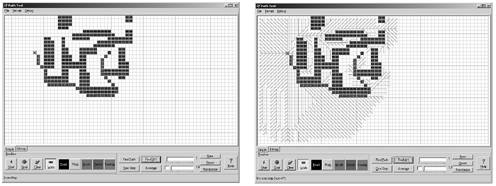
We start by resetting the distance and previous vectors. Then, we put all vertices in the Pending set and empty the Visited set. We must extract vertices from Pending to convert them to Visited, updating their paths in the process. For each iteration we extract the vertex from the Visited set that has the least distance to the source. This is done using the distance array. Remember that Pending is a priority queue sorted by distance. Thus, in the first iteration, the source (distance=0) will be extracted from the Pending queue and converted to Visited. Now, we take each edge from the extracted vertex u and explore all neighbors. Here we call the relax function, which makes sure the distance for these nodes is updated accordingly. For this first iteration, all neighbors of the source had distance set to infinity. Thus, after the relaxation, their distances will be set to the weight of the edge that connects them to the source. Then, for an arbitrary iteration, the behavior of the loop is not very different. Pending contains those nodes we have not yet visited and is sorted by the values of the distance. We then extract the least distance node and perform the relaxation on those vertices that neighbor the extracted node. These neighboring nodes can be either not-yet-expanded or already expanded nodes for which a better path was discovered. Iterating this process until all nodes have been converted from Pending to Visited, we will have the single-source shortest paths stored in the distance and previous arrays. Distance contains the measure of the distance from the source to all nodes, and backtracking from each node in the previous array until we reach the source, we can discover the sequence of vertices used in creating these optimal length paths. Dijkstra's algorithm is a remarkable piece of software engineering. It is used in everything from automated road planners to network traffic analyzers. However, it has a potential drawback: It is designed to compute optimal paths between one source and all possible endpoints. Now, imagine a game like Age of Empires, where you actually need to move a unit between two specified locations. Dijkstra's algorithm is not a good choice in this case, because it computes paths to all possible destinations. Dijkstra's algorithm is the best choice when we need to analyze paths to different locations. But if we only need to trace a route, we need a more efficient method. Luckily it exists and is explained in detail in the next section. A*A* (pronounced A-star) is one of the most popular and powerful problem-solving (and hence, path finding) algorithms. It is a global space-search algorithm that can be used to find solutions to many problems, path finding being just one of them. It has been used in many real-time strategy games and is probably the most popular path finding algorithm. We will thus devote some space to study it carefully. Before we do so, I'd like to examine some simpler algorithms such as depth or breadth first, so we get a better understanding of the problem and can visualize what A* does more easily. Let's begin by realizing that for the sake of path finding, states will be used to represent locations the traveler can be in, and transitions will represent unitary movements in any direction. Remember our good old checkerboard? Think about path finding in the same way. We have checkers that represent each portion of the map, and we can move one checker in any direction. So how many positions do we need to represent or, in other words, how many states do we need if we can only move on a checkerboard? A checkerboard consists of eight squares by eight squares, for a grand total of 64 possibilities. Games like Age of Empires are not very different: They use grids that also represent map locations. For Age of Empires, maps between 64x64 and 256x256 were common. A 64x64 grid yields 4,096 possible locations, whereas a 256x256 grid yields the infamous, 65,536 (two raised to the sixteenth power). The original algorithms devised to explore such structures were exhaustive: They explored all possibilities, selecting the best one between them. The depth-first algorithm, for example, gave priority to exploring full paths, so nodes were expanded until we reached the endpoint. A score was computed for that path, and then the process was repeated until all paths were computed. The name depth-first indicated that the algorithm would always advance, reaching deeper into the graph before exploring other alternatives. A different algorithm, called breadth-first, followed the opposite approach, advancing level-by-level and exploring all nodes on the same level before moving deeper. That worked well for games such as tic-tac-toe, where the number of steps is small. But what happens when you try to apply the same philosophy to something like chess? There's a huge number of states to explore, so this kind of analysis is very risky both in terms of memory and CPU use. What about finding a path? In a 256x256 map (which can be used to represent a simple, 256x256 meter map with a resolution of down to one meter), we would need to examine 65,000 locations, even though some of them are obviously not very good candidates. Are we really going to use regular state-space searches, where we will basically need to examine all those options one by one—in real-time? To make the response even more obvious, think not only about how many locations but also about how many different paths we need to test for. How many paths exist between two endpoints in a playing field consisting of more than 65,000 locations? Obviously, brute force is not a good idea in this situation, at least not if you want to compute this in real-time for dozens of units moving simultaneously. We need an algorithm that somehow understands the difference between a good path and a bad path, and only examines the best candidates, forgetting about the rest of the alternatives. Only then can we have an algorithm whose CPU usage is acceptable for real-time use. That's the main advantage of A*. It is a general problem-solving algorithm that evaluates alternatives from best to worst using additional information about the problem, and thus guarantees fast convergence to the best solution. At the core of the algorithm lies a node expansion policy that analyzes nodes in search of the complete path. This expansion prioritizes those nodes that look like promising candidates. Because this is a hard-to-code condition, heuristics are used to rate nodes, and thus select the ones that look like better options. Assuming we model the path finding problem correctly, A* will always return optimal paths, no matter which endpoints we choose. Besides, the algorithm is quite efficient: Its only potential issue is its memory footprint. As with Dijkstra's approach, A* is a short but complex algorithm. Thus, I will provide an explanation first, and then an example of its implementation. A* starts with a base node, a destination node, and a set of movement rules. In a four-connected game world, the rules are move up, down, left, and right. The algorithm is basically a tree expansion method. At every step, we compute possible movements until all movements have been tried, or we reach our destination. Obviously, for any mid-sized map this could require many states, with most of them being arranged in loops. Thus, we need a way to expand the tree in an informed way, so we can find the solution without needing to explore all combinations. This is what sets A* apart from the competition: It quickly converges to find the best way, saving lots of CPU cycles. To do so, it uses a heuristic—a metric of how good each node is, so better looking paths are explored first. Let's summarize what we have discussed so far. Starting with the base node, expand nodes using the valid moves. Then, each expanded node is assigned a "score," which rates its suitability to be part of the solution. We then iterate this process, expanding best-rated nodes first until these paths prove invalid (because we reach a dead-end and can no longer expand), or one of these paths reaches the target. Because we will have tried the best-rated paths first, the first path that actually reaches the target will indeed be the optimal path. Now, we need to devote some space to the rating process. Because it is a general-purpose problem-solving algorithm, A* uses a very abstract way of rating states. The overall score for a state is described as: f(node)= g(node) + h(node) where f(node) is the total score we assign to a node. This cost is broken down into two components, which we will learn to compute in the next few pages. For now, suffice it to say that g(node) is the portion that takes the past decisions into consideration and estimates the cost of the path we have already traversed in moves to reach the current state. The h(node) is the heuristic part that estimates the future. Thus, it should give an approximation of the number of moves we still need to make to reach our destination from the current position. This way we prioritize nodes, not only considering how close they are to the destination but also in terms of the number of steps already taken. In practical terms, this means we can have a node with a very low h value (thus, close to the target), but also a very high g value, meaning we took many steps to reach it. Then, another, younger node (low g value, high h value) can be prioritized before the other one because it obtains a lower overall score. Thus, we estimate it is a better candidate. Figure 8.4 provides a visual representation of the A* algorithm. Figure 8.4. The A* algorithm. Left: chosen path. Right: nodes required to compute it.
Notice how this method is valid for many problems, whether it's playing tic-tac-toe, building a puzzle, or computing paths. We add a component that accounts for our past behavior and estimate our future as well. For path finding problems, computing g is not really a problem; it's just the number of steps taken to reach the node. If we think in terms of a tree, it's the level in the tree. The heuristic part, on the other hand, is more complex. How do we estimate the remainder of the path without effectively examining it? For path finding, the main approach is to estimate remaining distance as the Manhattan distance between our current location and the destination. Remember that the Manhattan distance is the sum of the differentials in X and Z, as in the expression: Manhattan(p1,p2) = abs(p2.x-p1.x) + abs(p2.z-p1.z) If you try to visualize it, the Manhattan distance is the number of steps we would need to make if we were unobstructed. Thus, it is an optimistic heuristic. It always underestimates the effort required to reach our goal. This is an essential characteristic. If we can guarantee our heuristic is always underestimating (or giving the exact estimation) of the path ahead, A* always produces optimal paths. This is because it will try to find the path that more closely resembles (in terms of score) the estimate. Think about it for a second: A target node has a score of (N,0), which means N is the number of steps we needed to take, and 0 is the estimation of what remains. Using an estimate that is always optimistic forces us to reach the path with a minimal N value for the end node, which is what we are looking for. By the way, the Manhattan distance heuristic is a good choice for four-connected game worlds. If your world is eight-connected, Manhattan would not always be optimistic, so I'd recommend the classic Euclidean distance equation defined here instead: distance = sqrt( (p1.x-p2.x)2 + (p1.z-p2.z)2) The downside is the added cost of squaring and computing square roots, but convergence to the optimal solution always requires optimistic heuristics. We have seen how and why A* works. Now, let's propose a complete A* algorithm. Here is the pseudocode:
priorityqueue Open
list Closed
s.g = 0 // s is the start node
s.h = GoalDistEstimate( s )
s.f = s.g + s.h
s.parent = null
push s on Open
while Open is not empty
pop node n from Open // n has the lowest f
if n is a goal node
construct path
return success
for each successor n' of n
newg = n.g + cost(n,n')
if n' is in Open or Closed, and n'.g < = newg
skip
n'.parent = n
n'.g = newg
n'.h = GoalDistEstimate( n' )
n'.f = n'.g + n'.h
if n' is in Closed
remove it from Closed
if n' is not yet in Open
push n' on Open
push n onto Closed
return failure
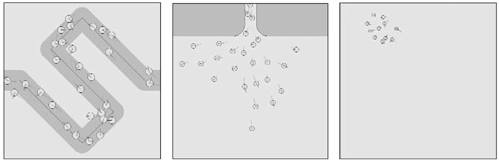
Notice how we use two data structures: Open is a priority queue that stores nodes we have visited, sorted by f-value. Thus, we can always extract the best-rated node. Then, we start by placing the start node in Open. We expand nodes in the while loop until no more nodes exist (that means we have explored the whole tree and did not find a solution, so we return failure). Then, at each step, we pop the best candidate from Open. We compute all successors from this node and rate them, storing them in Open as well. If the new rating is better than the previous one for the same node, notice how we overwrite the old value with the new one. This is useful when we have already visited one node, but a newer path yields a better score. As nodes are visited and expanded, we place them in Closed. We iterate this process until we have reached a goal or until no more nodes are in Open, meaning there is no solution. A* is a powerful algorithm. But it does not come without a host of problems of its own. First, it precomputes the whole path before even performing the first step. This makes it unusable for scenarios with dynamic geometry, such as collisions between soldiers, and so on. Second, A* always produces optimal results. This might seem like an advantage instead of a problem, but paths computed using A* sometimes look too perfect, and we need to modify the algorithm to add a degree of believability to the results. Third, A* computes the whole path in a single process. So how can we blend that with fog-of-war techniques? Many times we won't be seeing the whole path at once, so precomputing it using A* will simply be wrong. Our walking character will effectively see inside the fog-of-war to construct the path, which is cheating. Fourth, A* can create memory use problems. In any decent-sized map with obstacles, A* will explore lots of states to compute the best option. It is true that the end result will be optimal, but it will have claimed a high price in the process. A* is a memory-hungry algorithm, and considering its main use is found in strategy games where we need to move many units at once, this can become a pretty serious issue. Some variants have been proposed to deal with these issues. Two of the most popular variants are explained in the following sections. However, A* is currently the most widely used path finding algorithm: It is robust, it can handle both convex and concave geometry, and it is very well suited to games. Region-Based A*One problem with the A* algorithm is that if many obstacles block our advance, we need to expand a lot of nodes to reach our destination. This results in a very high memory footprint and low performance. We need to store lots of states. Two solutions have been proposed to deal with this problem. One solution involves tracing the path at a higher-abstraction level. The other involves tracing the path progressively, not expanding the whole state space at once. Region-based A* is explained in this section, and the next section describes Iterative-Deepening A* (IDA*). Regular A* decomposes paths in terms of primitive operations. In a four-connected scenario, we can move up, down, left, and right. Obviously, using such a low-level operator has a downside. Any reasonably sized path will be composed of many actions, and that means the search space will grow quickly. Now, A* does not necessarily need to use such primitives. We could implement A* using a different, higher-abstraction level space representation. For example, we could divide our game world into regions (be it rooms, zones in a map, and so on) and implement an edge or state transition whenever we move from one room to the other. Using a region-based A* algorithm is especially useful when coupled with convex map regions. If a region is convex, we can move between two endpoints without finding any obstacles in our way. This is the basis of Jordan's curve theorem. We can paint a line, and if the region is indeed convex, the line will cross it exactly twice. This means path finding inside the region can be handled in the simplest form—no obstacles to worry about, just walk in a straight line between the entry and exit point. The same idea can be extended to support convex obstacles in convex rooms as well. Imagine a square room full of columns. We can use A* to navigate the complete scenario and crash and turn (which works fine on convex obstacles) for intra-room navigation. This is an especially interesting result. If you think about it for a second, most obstacles in an indoors environment are either convex or can easily be considered convex by means of a convex hull/bounding box computation preprocess. Then, we would have the global correctness of A* while using a low-cost, low-memory footprint such as crash and turn for local analysis. The overall solution would also be faster to compute, because A* would converge faster in a smaller state space. Interactive-Deepening A*Another alternative to reduce space requirements in A* is to compute the whole path in small pieces, so we do not examine the whole search tree at once. This is the core concept behind IDA*, a very popular variant to the basic A* algorithm. In IDA*, a path is cut off when its total cost f(n) exceeds a maximum cost threshold. IDA* starts with a threshold equal to f(start node), which by the way is equal to h(start node) because g(start node) = 0. Then, branches are expanded until either a solution is found that scores below the cutoff cost or no solution is found. In this case, the cutoff is increased by one, and another search is triggered. The main advantage of IDA* over A* is that memory usage is significantly reduced. A* takes O(b^d), where b is the tree's branching factor and d is the number of levels in the tree. IDA* is just O(d) due to its iterative deepening nature. A Note on Human Path FindingTo get some perspective on path finding algorithms, let's stop and think about how humans trace paths in the real world. We tend to rely on very different methods than those used by machines. As mentioned earlier, tracing a path with or without a map really does make a difference—the difference from a local to a global algorithm. When using the global approach, our methods would not be very different from A*. But how do we trace paths in unexplored areas? Drop a tourist in the center of a city, give him a compass, and he'll find a way to a certain monument (provided we tell him in which direction to aim). How can he, and people in general, do that? To begin with, people use a hybrid local-global algorithm. It is local whenever we are exploring new ground. But we have the ability to build pretty good mental maps on the fly. When we walk through an unfamiliar neighborhood, we automatically store information about the places we see, so we can recognize them later. Thus, if we return to the same location (say, because we reached a dead end), we will be using a global path finding method. We have all the information about the area, and thus use it to our advantage. Formally, the main path planning routine is fundamentally a depth-first, trial-and-error algorithm, assisted by the maps we make in our mind. We try to advance in the direction the goal seems to be, and if we reach a dead end, we back up using the map and try a different strategy. Different people use slightly different strategies, but the overall algorithm stays the same. The pseudocode for such an algorithm would be something like this: while not there yet, detect the direction where the target is at choose from the unexplored available paths the one that seems to move in the right direction explore the path, storing the features of the areas we visit in an internal map if we reach a dead-end, back-up to the latest junction, marking everything as already tried (and failed) go to step 3 end while With quite a bit of precision, the algorithm we use enables us to find our way around in places we've never visited before. And I might add, it works remarkably well as long as we have the ability to remember places we just visited. As you can see, the algorithm does not look very hard to implement. But how do you store relevant information for later use as a map? What is relevant? How do we store map data? Humans are light years ahead of computers when it comes to representing and working with symbolic information. We can remember locations, sounds, and people, and build accurate maps based on them. We can handle types and amounts of information that a computer, as of today, cannot deal with well. Notice, however, that the human path finding algorithm is essentially local, and thus does not guarantee an optimal path will be found. As we repeat the same journey or simply wander around the neighborhood, we will gather more information for our map, thus making path finding less local and more of a global strategy. However, even with the imperfections of the map making, the algorithm is light years away from its philosophy from the mathematical perfection of an algorithm like A*. On the other hand, there is a clear reason for using algorithms such as A*. Most games using path finding need it for military simulations, where the AI must be solid and compelling. Keep in mind that games are not about realism: They are about having a good time, and no one wants soldiers to get stuck trying to find a way to the frontline—no matter how realistic that might be. After all, people do get lost in cities all the time, but programmers don't want that to happen in the middle of a game. However, it is likely that the near future will bring more humanlike path finding to games, where behavior is not so much based in tactics but in conveying the complexity of real creatures. Group DynamicsWe will now move higher on the abstraction scale to study how we can emulate the movement patterns of groups of entities, whether it's a highly unorganized herd of mammals or a Roman cohort performing complex formations. We will not use the synchronization ideas from the previous chapter, because they do not scale well. Synchronizing two soldiers is qualitatively different from trying to move a wedge of 500 cavalrymen, so a whole different approach must be devised. We will start with a classic animal behavior algorithm and then move on to formations in the next section. BoidsOne of the best examples of synthetic group behavior can be found in the boids algorithm introduced by Craig W. Reynolds in the 1990s. The algorithm was initially designed for creating movie special effects and was used in movies like Disney's The Lion King. The boids algorithm became a cornerstone in real-time group dynamics and was a huge influence in many movies, such as Starship Troopers. As years went by, the boids algorithm slowly found its way into computer games, from simple flocking birds in Unreal to complete group dynamics for large-scale strategy games. You can see many types of boids-driven behaviors in Figure 8.5. Figure 8.5. Different types of boid-like algorithms: follow the leader, enter through a door, follow a path.
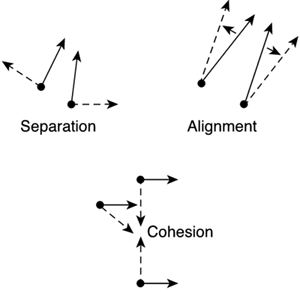
The boids algorithm allows the real-time simulation of flocks, herds, schools, and generally speaking, any creature that acts as part of a group with hardly any room for individuality. Interestingly enough, the boids algorithm can efficiently simulate traffic jams on a highway, pedestrian behaviors, and many other human activities as well as simple animal behavior. The core hypothesis of the boids system is that the behavior of a group of individuals is largely governed by a relatively small set of simple rules. Birds, goats, and even human beings are not extremely intelligent when it comes to working in groups. Thus, Reynolds believed that the apparent complexity must simply arise from relatively straightforward mechanisms. After some research, he found that flocking behavior could easily be modeled with as few as three rules:
The combination of these three rules (depicted in Figure 8.6) can effectively simulate any flock. The system is really simple to code. Notice that a boid does not even have an internal state variable. Each computed frame starts from scratch, so it makes no sense for the bots to have a working memory. On the other hand, some changes need to be made in order to increase the boids system's expressive potential. For example, one of the members of the formation must be a scripted AI (or even the player). We need someone to generate the influence field so the others will conform to this behavior. Another interesting issue is the handling of a more complex system. To analyze this, we need to fully understand how boids works, and even better, why. Figure 8.6. The three rules of boids.
To better understand boids, you need to think about them as analogies to fields or zones of influence. Imagine that each boid is actually a charged particle. It is repelled by a strong (but quickly diminishing) field, so it never collides with another particle of the same sign, and it has an attractive force toward the center of gravity (in the boids case, the center of the flock). Thus, we can rewrite most of the boids algorithm in terms of attractions and repulsions. Even more complex and involved simulations can be created by just adding layers and layers of information to the core boids algorithm. Imagine, for example, two types of birds, pigeons, and hawks. Hawks try to catch pigeons, which in turn try to escape as soon as they see an incoming hawk. We can simulate this behavior by just adding a fourth rule to the core boids system. It is a special-case separation rule, which affects much higher distances than the traditional separation rule explained in the original formulation. If you have followed this example, you will see how this hawk and pigeon approach allows us to elegantly incorporate obstacle handling in our boids code. Obstacles can be modeled as an extra type of entity, so other entities just feel a strong repulsive force toward them. Notice how a group of birds will effectively avoid the collision using the obstacle information. On the other hand, once the obstacle has been avoided, the third rule (cohesion) will play a key role, ensuring that everyone is working diligently to reestablish the formation. Let's now adapt these methods to groups of humans, quite likely in the context of military strategy. Formation-Based MovementMoving in formation is a bit more involved than acting on an individual basis or acting like a flock of birds. Any error in our alignment or speed will generate unwanted collisions with other members of our unit and quite likely will end up breaking up the group. Several approaches can be used to implement formation-based navigation. In one approach, you can totally discard the individual component and make the whole squadron act as a single soldier. The AI is assigned to the squadron, so each soldier is just placed wherever needed. For example, imagine that we need to control a squadron consisting of 60 men in 6 ranks, 10 men per rank. We represent the squadron by its barycenter and yaw vector. Thus, here is the rendering code needed to paint each soldier individually:
#define SPACING 2
for (int xi=0;xi<COLUMNS;xi++)
{
for (int zi=0;zi<RANKS;zi++)
{
point pos(xi-(COLUMNS/2),0,zi-(RANKS/2));
pos=pos*SPACING;
pos.rotatey(yaw);
pos.translate(barycenter);
}
}
This approach has a limitation, however: We cannot assign individual behaviors. For example, our troops will fight in perfect formation and will not avoid obstacles on an individual level. The whole troop will change its trajectory to avoid a tree, for example. Thus, more powerful ways of dealing with group dynamics must be devised. Adapting the ideas from the boids algorithm, we can represent group dynamics for humans by means of a summation of potential fields. Here, we will resolve locomotion as the addition of several fields of influence, such as:
By adding the influence of these three fields, you can achieve very realistic formation-based movement. A column might break to avoid an obstacle, only to merge again on the opposite side. Formations can perform rotations, and so on. The main pitfall of such an approach is that obstacle geometry must be kept simple, so we can generate potential fields efficiently. Concave objects will definitely not be modeled. Another issue comes from computing the repulsion with obstacles and enemy units. Here we will need an efficient data representation to ensure we can compute these fields without having to resort to NxN tests. A spatial index can definitely help us in this respect. |
|
|
Ajax Editor
JavaScript Editor