Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
A Generic Graphics PipelineThe first part of the chapter dealt in detail with the data types and structures we will be using in our graphics engines. Now it is time to move on and describe the algorithms we will need to render the data efficiently. This is a vast subject, and we will be discussing it in the following three chapters as well. So, I will begin by describing a global framework for a graphics pipeline, from which any specific graphics engine can be built by refining the desired components. Generally speaking, we can decompose any 3D pipeline in four stages:
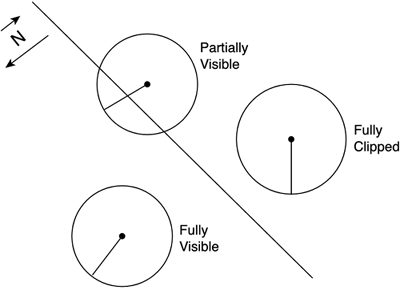
By combining these processes, we can make sure we paint the desired scenario at a frame rate suitable for real-time games. By refining the design of each component (and the relationships between them), we can achieve a broad result spectrum. ClippingClipping is the process of eliminating unseen geometry by testing it against a clipping volume, such as the screen. If the test fails, we can discard that geometry because we will know for sure it will not be seen. Obviously, the clipping test must be faster than drawing the primitives in order for clipping to provide a significant speedup. If it took us longer to decide whether to paint or not to paint the primitive, clipping would be an unneeded burden. There are several ways to do clipping for games, depending on how early in the pipeline you perform the test. In general, it is important to clip geometry as soon as we can in the graphics pipeline, so we can reduce data transfer to the GPU, and ultimately, the rasterization of unseen primitives. Clipping can provide a very significant speedup to any graphics engine. But exact results vary between different clipping methods (and engine types). For example, a game like Tekken, where most of the geometry is visible all the time, will not benefit from clipping. As a corollary, games with small, spatially localized data sets will not be able to eliminate lots of geometry in a clipping pass. This would apply to fighting games, but also to many other genres. Let's look at a more favorable case to see the real benefit of clipping. Consider a 3D game that takes place in the XZ plane, such as most first-person shooters (FPS), driving simulators, and so on. Here, we are surrounded by geometry that extends in all directions in a more or less homogeneous way. This is the ideal scenario for a clipping algorithm: large, homogeneous levels that we can traverse freely. The reason is simple: In this case, lots of geometry will be outside the clipping volume behind our back or to the sides. For example, imagine that you want to clip against your camera to discard unseen primitives. The camera has a horizontal aperture of 60º, which would be pretty much standard. Taking an average case, we would be seeing 60/360 of our full level, so only one of every six primitives would be processed. This means that we can concentrate on 17 percent of the geometry and discard the remaining 83 percent of the data. Clearly, clipping makes a big difference in this case. All games with large levels, such as role playing games (RPGs), FPSs, real-time strategy (RTS) games, space simulators, driving games, and so on, will yield equally interesting results. Now that we know clipping can provide a very significant performance boost to our engine, let's explore how clipping can be implemented. Triangle ClippingWe will start by clipping each and every triangle prior to rasterizing it, and thus discard those that lie completely outside of the clipping frustum. Again, this only makes sense if the triangle clipping is significantly faster than the rasterization process. However, even if this is the case, the triangle-level test will not provide very good results. But let's discuss it for a second because it will provide some useful concepts for more advanced methods. You should know that almost all current graphics accelerators provide triangle-level clipping tests for the frame buffer. This means that you can safely send all your geometry to the graphics chip, where nonvisible fragments will be discarded. Thus, only visible portions will take up processing time in the rasterization engine. You might think that you will get great performance with no coding because the hardware clipper will get rid of unseen triangles. Unfortunately, great performance rarely comes for free. Hardware clipping your triangles is a good idea, but you will need some code to ensure top performance. The reason is simple: In order to decide whether to paint or not paint a triangle, you must send it to the graphics chip, where it will be tested. This means your triangle (whether it's seen or not) will travel through the data bus, which is slow. However, clipping geometry at the triangle level requires sending it through the bus to the graphics card, which is where the clipping is performed. In other words, using triangle-level clipping forces us to send lots of invisible triangles to the card, just to be clipped there. Clearly, we are not using the bus very efficiently. This is where object-level clipping can help. Object ClippingAs mentioned earlier, triangle clipping is limited by the bus speed. So, we will need a new method that allows us to clip the geometry before it is sent to the graphics card. Additionally, this method must work on a higher abstraction level than triangles. Software testing each triangle is too slow for rich, real-time games that display millions of triangles per second. The preferred approach is, obviously, to work on an object level. Rejecting a complete object, which is possible in the thousands of triangles, with a simple test will provide the speed boost we are aiming for. Essentially, we will decompose our scene into a list of objects and test each one as if it were a fundamental primitive for clipping. As you will soon see, some easy tests can tell us if a whole object is completely invisible so we can discard it. For those objects that lie completely or partially within the clipping volume, hardware triangle clipping will automatically be used. This approach is not limited to objects in the "game logic" sense of the word. We can cut any large geometry block into spatially localized chunks and consider them as objects for our clipping routines. This is especially helpful for level geometry processing. We can cut the complete area into rooms, including walls and ceilings, and reject nonvisible data very quickly. The core idea behind object clipping is simple: For each object, compute a simpler volume that can quickly be clipped. This volume will represent the boundary of the object. Thus, performing the test on the volume will provide an easy rejection test. Sometimes, the bounding volume will be visible but the object won't, yielding a "false positive." But the benefits clearly outperform the added cost of these false positives. So why don't we use the actual geometry for the clipping test? The answer is that regardless of the clipping strategy you used, you would end up with a computational cost that would depend (in terms of cost) on the geometry complexity. For instance, testing a 1,000-triangle object would be faster than testing a 10,000-triangle object, and that's an unpleasant side effect. Bounding volumes provide us with constant-cost clipping methods, so we can keep a stable frame rate regardless of the object's inner complexity. Many bounding objects can be used, but spheres and boxes are by far the most common. Let's study their properties and tests in detail. Bounding SpheresA bounding sphere is defined by its center and radius. Given the six clipping planes mentioned earlier, rejecting a sphere is very easy. Let's start with a single plane, represented by the equation: Ax + By + Cz + D = 0 where A,B,C are the normalized components of the plane normal, and D is defined using A,B,C and a point in the plane. For a sphere with its center in SC and radius SR, the following test: A · SCx + B · Scy + C · SCz + D < -SR returns true if (and only if) the sphere lies completely in the hemispace opposite the plane normal, and false otherwise. You can see a graphic representation of this in Figure 12.3. Figure 12.3. Clipping spheres against a plane.
Notice how this test requires only three multiplies, four additions, and one compare. Interestingly, this test is a logical extension of the point versus plane test, which for a point P would be: A · Px + B · Py + C · Pz + D < 0 This would return true if (and only if) point P was in the hemispace opposite the plane normal. Returning to our main argument, we can use the sphere versus plane test to implement a very efficient sphere versus view frustum. Here I will use the view frustum notation we used in preceding sections. The pseudocode would be:
For each clipping plane
If the sphere is outside the plane return false
End for
Return true
In a strict C implementation, the preceding code would translate into:
for (i=0;i<6;i++)
{
if (fr[i][0]*sc.x+fr[i][1]*sc.y+fr[i][2]*sc.z+fr[i][3]<=-sr)
return false;
}
return true;
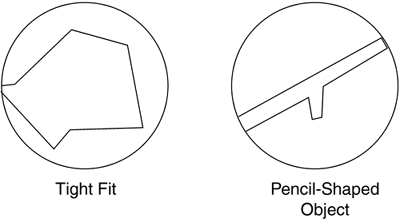
The first conclusion reached from the preceding analysis is that testing against a sphere is inexpensive. In fact, the cost is the same as testing a point. This makes spheres a good idea for tests that have to be performed frequently. A second advantage of using spheres is rotation invariance. Imagine that you have a spaceship you need to clip against the view frustum. The bounding sphere will remain the same regardless of the orientation of the ship; rotating the object will not affect the bounding volume. This is another handy property of spheres. Spheres are not, however, perfect. For example, they tend not to fit the geometry well, yielding lots of false positives. Imagine a pencil-shaped object, as shown in Figure 12.4. In this case, using a bounding sphere will create a false impression of size, which will translate into lots of false positives in our clipping routines. Generally speaking, spheres work better with geometry that occupies the space in a more or less homogeneous fashion—objects that occupy all directions of space similarly. Figure 12.4. Pencil-shaped object.
Bounding BoxesAs an alternative to spheres, we can use boxes to clip our geometry. Boxes generally provide a tighter fit, so less false positives will happen. In contrast, the clipping test is more complex than with spheres, and we don't have rotational invariance. So clearly, choosing between spheres and boxes is not a black-and-white scenario. Boxes can either be axis aligned or generic. An axis-aligned bounding box (AABB) is a box whose faces are parallel to the X,Y,Z axes. They are the simplest form of box, and thus the easiest to compute. To compute an AABB for a set of points, the following algorithm must be applied. From all the points,
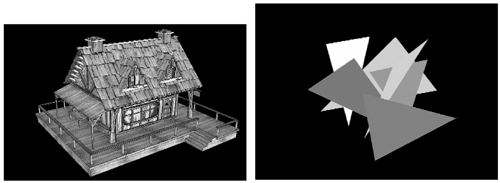
The AABB is defined by two points: one that will store the minimum values and another one for the maxima. The visibility test is significantly harder than for spheres. We need to test whether any vertex is inside the frustum while keeping in mind that a box with all vertices outside the frustum can still be visible if it totally encloses it. Here is one of the possible tests for such a routine: bool CubeInFrustum( float x, float y, float z, float sizex, float sizey, float sizez ) { int p; for( p = 0; p < 6; p++ ) { if( frustum[p][0] * (x – sizex/2) + frustum[p][1] * (y – sizey/2) + frustum[p][2] * (z In the preceding code, x, y, z is the center of a box of sizes: sizex, sizey, sizez. Notice how the frustum still contains the six clipping planes given the current camera position. CullingCulling allows us to eliminate geometry depending on its orientation. A well-executed culling pass can statistically eliminate about one half of the processed triangles. As an added benefit, the culling pass can be connected to a clipping stage, providing the combined benefit of both stages. To better understand culling, we must first discuss the nature of 3D objects. Compare both sides of Figure 12.5, which represent two 3D entities. In the right figure, you can see a large number of triangles laid out in a chaotic, unorganized way. On the left is a 3D model of a house. Clearly, when we talk about a 3D object we are referring to the figure on the left. But what are the characteristics of these objects? Figure 12.5. House mesh versus polygon soup.
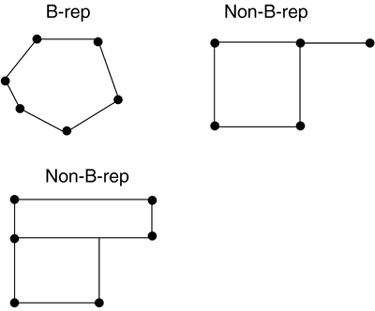
Primarily, a properly defined 3D object uses its triangles to fully divide the space in two: a volume enclosed by the object (which we will call inside) and the remaining area (the outside). This is what we will call the boundary representation (B-rep) of an object. As a corollary of this property, both subspaces (inside and outside) are mutually disconnected: The object has no openings or holes that allow us to look inside. We can have a passing hole that allows us to cross the object, but we will never see the inside of the object. You can see examples of B-reps and non-B-reps in Figure 12.6. Figure 12.6. B-rep versus non-B-rep geometries.
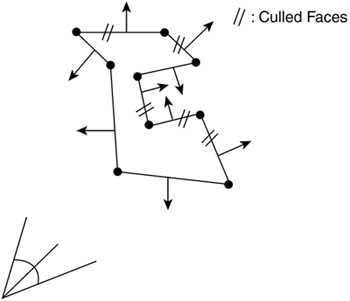
Another important property of a well-formed object is that the vertices of each triangle are defined in counterclockwise order (as seen from the outer side of the object). Applying the polygon winding rule, this means that face normals should point outward. When doing a simple cross product, we can automatically generate per face normals. Having defined these fundamental properties, we can now move on and enumerate the following theorem: Given an arbitrary 3D well-formed object, the faces whose normals are pointing away from the viewpoint will be occluded by other faces, and thus can be culled away. The simplest (and most frequently used) form of culling takes place inside the GPU. As triangles are received, their winding order is used to determine the direction of the normal. Essentially, the order in which we pass the vertices defines the orientation (and hence the normal) of the triangle. This direction is used to discard back-facing primitives. Notice how the GPU can perform triangle culling even if we do not provide the normals of the triangles: The order of the vertices is enough. The reason is simple: Some methods use per triangle normals, others use per vertex (for example, Phong shading). Thus, the algorithm for rejecting primitives has to be independent of the normal format. After reading the preceding section on clipping, you should expect a section on object-level culling, so we can work with higher abstraction on the pipeline. But object-level culling is by far less popular than object-level clipping. There are several reasons for this:
Object CullingThe basis of object-level culling involves rejecting back-facing primitives at a higher abstraction level. To do this, we will need to classify different triangles in an object according to their orientation. This can either be done at load time or as a preprocess. The result of this process will be a series of clusters of similarly aligned primitives. Then, the rendering loop will process only those clusters that are properly aligned with the viewer. Several methods have been designed to create these clusters; all of them trying to do a partition of the normal value space. Because normals are unit vectors, their longitude and latitude are used. To prevent distortions at the poles, one popular method uses a cube as an intermediate primitive. Each face of the cube is divided into subfaces like a checkerboard, and then vectors are computed from the center of the cube to the edge of each square. Each square represents a range in the longitude–latitude normal space. We only need to sort our triangles into these clusters, and then paint only the clusters that can potentially face the viewer. You can see this approach in action in Figure 12.7. Figure 12.7. Object culling.
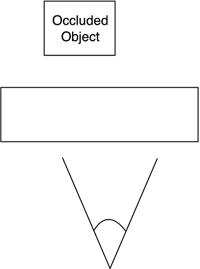
Occlusion TestingClipping and culling can dramatically reduce the scene's triangle complexity. But some redundant triangles can still survive those tests. If we do not implement additional measures, all triangles lying in the view frustum facing the viewer will be considered valid. But what if two visible, camera-facing primitives overlap each other? You can see this situation depicted in Figure 12.8. In this case, the pipeline will process both, consider them valid, and paint them using the Z-buffer to properly order them. Evidently, only one of them will be seen (the one closest to the viewer, sometimes referred to as the occluder). So we will need to process both, and only in the fragment rasterization stage decide which one will stay on the Z-buffer and get painted. We will have committed one of the deadly performance sins: overdraw. Figure 12.8. Occlusion.
The best way to picture overdraw is to think of an FPS that takes place indoors in a maze full of twisting corridors. In these types of games, our line of sight is usually limited to a few meters. There's always one corner or gate to ensure we don't see what we are not supposed to. In graphics jargon, these scenarios are "densely occluded." Now, imagine that we do not perform some kind of occlusion testing on the depicted situation. Clearly, performance from the viewpoints marked as A would be poor, whereas performance on B would be very good. To avoid this situation, FPS designers try to ensure that approximately the same number of triangles are visible onscreen at any given time. And having a good occlusion policy is fundamental to reaching this goal. Many occlusion prevention policies largely depend on the kind of game you are building. Many of the tests (such as Potentially Visible Set [PVS] culling, portal rendering, and so on) are designed to work in indoor scenarios, and some of them (the lesser part) are designed for the great outdoors. So, we will leave those for the following chapters and concentrate on universal policies. Some hardware has built-in occlusion testing options. This is the case in some Hewlett Packard cards as well as NVIDIA's cards starting with the GeForce3 onward. ATIs from the 8500 upward can also perform occlusion testing, which can be handled by both DirectX and OpenGL. Take a look at Chapter 13, "Indoors Rendering," for a complete tutorial on enabling hardware occlusion. Using the hardware is an extremely powerful and flexible way of performing occlusion tests and is growing quickly in popularity. Essentially, it works on an object level and allows you to discard large blocks of geometry with a single query. The interface is relatively straightforward: Each object must be completely surrounded by a bounding object, which can be an AABB, a sphere, a generic bounding box, a convex hull, and so on. In fact, any geometry that completely encloses the object can be used. We must then run the occlusion query by sending the bounding object down the graphics pipeline. This object will not be painted, but instead will be tested against the Z-buffer only. As a return from the test, we will retrieve a value that will tell us:
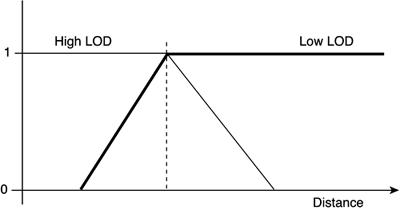
So, we now have a trivial occlusion rejection query. Draw the geometry front to back (so large occluders are painted first), and then paint the geometry testing for each object if its bounding volume (BV) will alter the Z-buffer. If the BV will not affect the results (because it is fully behind other objects), we can reject the object and skip to the next one. Needless to say, the speedup achieved by hardware occlusion culling techniques can be huge, especially in dense scenes with lots of occluders. As usual, this test can yield false positives. There is a minimal chance that the BV will be visible, but the object will not. However, being able to reject most occluded objects with a single test is such an advance that false positives are definitely a minor issue. Resolution DeterminationWhen I think about realism in a computer game, I always think of Yosemite National Park in California—huge mountains and thousands of trees in a richness and variety that makes any visitor feel tiny in comparison. I don't think we will be reaching that level of complexity in some time. So, it's a perfect example to show how resolution and level-of-detail (LOD) techniques work. Let's imagine for a second that you actually tried to do a game set in Yosemite with the tools we have seen so far. You do some aggressive clipping, which, because your camera has an aperture of 60º, reduces complexity to one-sixth of the total triangles. Then, some serious culling chops that in half to reach one-twelfth. Also, you have a dreamlike occlusion calculator. Let's daydream for a second and imagine that after the three stages, you have reduced the visible triangle counts to about one-fiftieth. Now, how many triangles does Yosemite have? I know it might sound absurd, but follow me through this exercise because it will be a true eye-opener. Let's assume you do a 20kmx20km square terrain patch, with terrain sampled every meter. If you do the math, you will see we are talking about a 400 million triangle map. Not bad, but let's not stop there. Now comes the fun part: trees. Trees are hard to get right. From my experience, a high-quality, realistic tree should be in the 25,000 triangle range (yes, each one). Assuming one tree for every 20 meters, that yields 1 million trees for the whole park, or even better, 25 billion triangles per frame. At a very reasonable 30 frames per second, the triangle throughput of our engine is…well, you get the idea, right? We can reduce that by 50 using conventional techniques. We could even reduce it by 500, and still the cost would be prohibitive. At the core of the problem there's a brute-force approach that has resulted in this exponential growth scheme. Assuming the trees are about 50 meters high and remembering that objects have a perceived size that is inversely related to the distance, squared, we will reach the conclusion that our magnificent tree, seen from one kilometer away, is almost invisible. So, it didn't really make any sense to use 25,000 triangles for it, right? These kinds of tactics are what resolution determination is all about. Clipping, culling, and occlusion tests determine what we are seeing. Resolution tests determine how we see it. Our Yosemite game is an example of the ideal scenario for multiresolution strategies: an outdoor game with little or no occlusion and a very high triangle count. At the core of such a system lies the concept of priority: We can assign more triangles to items in the front, using lower quality models for those in the back. The human visual system tends to focus on larger, closer objects (especially if they are moving). If done right, we can make the player think the whole scenario is as detailed as the closer elements, and thus create the illusion of a larger level. Many multiresolution strategies exist, depending on the scenario. Some methods are better suited for outdoors landscapes, whereas others are designed to work on individual objects. But generally speaking, all consist of two components. First, a resolution-selection heuristic that allows us to assign relative importance to onscreen objects; and second, a rendering algorithm that handles the desired resolution. Focusing on the heuristic that sets the resolution level, we could begin by computing the distance from the object to the viewer and use that as a resolution indicator. As the object moves away from the viewer, its resolution can change accordingly. But this method is far from perfect. Imagine that you are looking at the San Francisco Bay, with the Golden Gate Bridge looming near the horizon. The bridge might be very far away, but it's huge, so reducing its resolution can have undesirable side effects. Thus, a more involved heuristic is required. This time, we project the bounding box of the object onscreen and calculate the area of the projected polygon. An object's importance has to do with perceived size, not with distance: A small onscreen object can be painted at a lower level of detail than a huge object. Thus, we can use this projected area as the selection criteria for the multiresolution algorithm. With this strategy, a case like the Golden Gate Bridge, mentioned earlier, will be treated correctly. If we are looking at the bridge from a distance and a car is crossing the bridge, we will assign a much lower detail level to the car than we will to the bridge, even if they are more or less at the same distance from the viewer. Once the selection criteria have been evaluated, it is then time to apply the painting policy. Here the criteria largely depend on the kind of primitive we are painting because different primitives employ completely different rendering strategies. Terrain renderers, for example, use very specific techniques such as Continuous Level Of Detail (CLOD), Real-time Optimally Adapting Meshes (ROAM), or GeoMipMapping. Because these are involved subjects, Chapter 14, "Outdoors Algorithms," has been devoted to outdoors renderers. However, primitives broadly conform to two different families of solutions. We can choose either a discrete approach, where we simply select the best-suited model from a catalog of varying quality models, or we can use a continuous method, where we can derive a model with the right triangle count on the fly. The first method will obviously be memory intensive, whereas the second will have a lower memory footprint but a higher CPU hit due to the inherent calculations. Let's examine both in detail. Discrete Level of Detail PoliciesUsing the discrete approach, we would have a table with different models (anything from two to five is common) of varying quality. These models can easily be computed using standard 3D packages, because all of them offer excellent triangle-reduction options. Models are stored in an array, top-quality first. Each model must be assigned an associated numeric value that represents the upper limit that the model is designed for (either in distance or screen area). Then, in the painting routine, we only have to compute the chosen metric and scan the list to see which model suits us best. This first technique can be seen in hundreds of games, especially those with large viewing distances where the size of the displayed items can vary a lot. The characteristic is a more or less noticeable popping that happens whenever there is a change in the displayed model. Some simple techniques exist that eliminate the popping and provide the continuous look without the CPU cost. One of the most popular techniques is alpha-blended LODs. The idea is to start with the classic discrete approach as explained in the previous paragraph. Then, additional code is added to ensure no popping is visible. The new code is designed to ensure a smooth transition between models by alpha-blending them. The idea is simple and can be seen in Figure 12.9. Instead of storing only the distance at which models are swapped, we store a pair of values that represent the beginning and the end of the transition. As we move inside that range, the two models are blended accordingly, so only model A is shown at one end of the range, and model B is shown at the opposite end. Carefully selecting the blending function ensures a smooth, almost unnoticeable transition. Figure 12.9. Alpha-blended LODs.
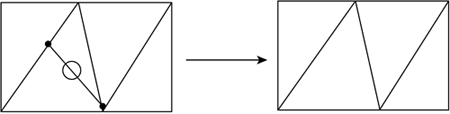
Alpha-blended LODs have the advantage of building upon the simple, well-analyzed technique of discrete LODs. Thus, they are simple to code and provide excellent results. The only downside is that painting two objects during the transition has a significant GPU overhead. But this technique is gaining ground rapidly, surpassing in popularity the mesh reduction algorithms. Continuous Level of Detail PoliciesTo avoid the popping completely, we can implement a continuous method, which can decrease the triangle count on the fly and thus generate the right model for each distance. There are many different approaches to reach this goal; all of them involve a good deal of math and computational geometry. To begin with, we will need to store more information about the object to perform the triangle reduction tests at an interactive frame rate that includes edge information, neighboring data, and so on. To better understand continuous LOD strategies, we will now explore one of the most popular methods in some detail. This method (called Edge Collapsing) involves detecting edges that carry little information and eliminating them by joining the two end vertices into one. By doing this to a solid model, we are eliminating two triangles, two edges, and one vertex. By performing this operation sequentially, we can reduce our model's triangle count to whatever fits us best. Collapsible edges should be selected from those that carry the least information. Thus, because an edge can be shared between two (and only two) triangles, we are looking for those edges where the support planes from their neighboring triangles are almost coplanar, or at least the angle between those planes is smaller than a threshold. Once the desired edge is found, two different collapse operations can be performed. You could collapse one vertex into the other, as shown in Figure 12.10. Again, the vertex that will be destroyed in the process is the one whose neighboring faces are more coplanar (thus conveying less information). Another strategy is to collapse the edge to a new vertex (thus both old vertices are destroyed) located along the edge. This second strategy can yield better results at a higher computational cost. Figure 12.10. Edge collapse.
This process is not trivial when you want to eliminate more than one triangle. Either you do N loops, eliminating one edge at each iteration (which is costly), or you do a composite loop where you take away many triangles at once (which is hard to code). However, there is a significant CPU hit involved in this process. A way to lower the computational cost is to use temporal coherence. Perform the edge collapse only once every few frames, using a metric. Every time you do the math, you store the distance (or screen area) of the object, and before you perform the calculation again, you make sure there has been a significant difference between the previous metric value and the current value. The pseudocode for this strategy would be
// global variable
float distance, area;
// rendering loop
newdist = compute distance to object
newarea = compute screen area of object
if ( abs(newdist-distance)>DISTANCETHRESHOLD ||
abs(newarea-area)>AREATHRESHOLD)
{
perform edge collapse
distance=newdist
area = newarea
}
paint object
This temporal coherence technique can greatly speed up your code because the costly edge-collapse routine will only be calculated when it is necessary. Whichever option you use, real-time triangle reduction policies are sometimes described as a total solution and a panacea. On one hand, this is partly true, because they allow us to get rid of the popping and have the exact triangle count that we need. But an objective analysis will also reveal some interesting drawbacks. First, there is a significant CPU hit in any reduction strategy: Edge collapsing is a pretty involved process if you want to get rid of many polygons at once. Second, there are texturing issues involved: What happens if the two vertices shared by the edge are made of two different materials? There are many caveats similar to this one, which limit the scope in which we can use the strategy. Transform and LightingBefore being displayed onscreen, the geometry stream passes through transform and lighting stages. These stages are hardware accelerated in current accelerators (GeForces, Radeons), but some older hardware performed these routines in the software driver. The transform stage is used to perform geometric transformation to the incoming data stream. This includes the familiar rotation, scaling, and translation, but also many other transforms. In its more general definition, a transform can be described as a 4x4 matrix, which left-multiplies incoming vertices to get transformed vertices back. This stage also handles the projection of transformed vertices to screen-coordinates, using projection matrices. By doing so, 3D coordinates are converted into 2D coordinates, which are then rendered to the screen. The lighting stage implements lighting models to increase the realism of the scene. Most current APIs and GPUs offer hardware lighting, so we can define light sources and surface properties, and have illumination applied at a zero CPU hit. Unfortunately, only per-vertex, local models of illumination can be applied directly in today's hardware, so no real-time ray tracing or radiosity is performed on the hardware automatically. Sometimes, per-vertex local lighting will not be enough for your game. You might want a more involved global illumination look (such as radiosity in Quake II) or special effects that must be computed per pixel. Then, you might decide to override the hardware lighting model and use your own lighting policy. Unsurprisingly, per-vertex techniques are losing ground as better hardware lighting is introduced (especially programmable pipelines with vertex and pixel shaders). However, many games still use these approaches. One of the most popular is lightmapping, which stores the lighting information in low-resolution textures that are then painted on top of the base textures using multitexture techniques. Lightmapping allows per-pixel quality at a reasonable cost, and when coupled with a radiosity preprocessor, yields strikingly good results. Light mapping is fully explained in Chapter 17. RasterizationRasterization is the process by which our geometry is converted to pixel sequences on a CRT monitor. Since the advent of the first consumer accelerators, this process is performed fully in hardware, so the only task left to the programmer is the delivery of geometry to the GPU. This is very good news because rasterizing triangles is extremely time-consuming when done in software. Today, there are even several ways to perform this task, each one suited to different scenarios—thus having specific advantages and disadvantages. As a first, introductory option, geometry can be delivered in an immediate mode. Under this mode, you will be sending the primitives (points, lines, triangles) individually down the bus, one by one. It is the easiest to code, but as usual offers the worst performance. The reason is that sending data in many little packets results in bus fragmentation. Because the bus is a shared resource between many devices in your computer, it is not a good policy. However, a complete example of a triangle delivered in immediate mode in OpenGL is provided: glBegin(GL_TRIANGLES); glColor3f(1,1,1); glVertex3f(-1,0,0); glVertex3f(1,0,0); glVertex3f(0,1,0); glEnd(); The preceding code would paint a white triangle on the screen. Notice how you are using six commands, and how each vertex and color is specified separately. Next in the performance scale are packed primitives, which are available in both OpenGL and DirectX under different names. In OpenGL, we call them vertex arrays, whereas DirectX refers to the same concept as vertex buffers. These primitives allow us to pack all the data in one or more arrays, and then use a single call (or very few calls) to deliver the whole structure to the hardware. Because the arrays can be sent in a single burst to the hardware, and there are fewer API calls, performance is greatly increased. The most basic form of array uses one array per type of data. Thus, to deliver a mesh with vertex, color, and texture information to the hardware, you would need three separate arrays. After all the arrays have been loaded and exposed to the graphics hardware, a single call transfers them and does the rendering. Keep in mind that vertex arrays store their data in system memory, so you are accessing the bus every time you want to draw the desired object. As an improvement, arrays can use the indexing policy explored at the beginning of this chapter. This way the amount of data delivered to the hardware is smaller, and the performance gain is bigger. One alternate strategy is to use interleaved arrays, in which all the information is encoded in a single array, interleaving the different types of information. So, if you need to send vertex, color, and texture information, your geometry stream would look something like this: V[0].x V[0].y V[0].y C[0].r C[0].g C[0].b T[0].u T[0].v (...) Using interleaved arrays, you can reduce the number of calls required to deliver the geometry. There might be a performance increase, but overall, this strategy would be quite similar to regular vertex arrays. The most popular use of interleaved arrays is the implementation of vertex buffers in Direct3D. All the techniques we have explored so far share a common principle: Geometry is delivered to the hardware from system memory on a frame-by-frame basis. Although this is appropriate in many situations, remember that bus bandwidth is usually the bottleneck, so we must avoid using it as much as we can. Imagine, for example, a car racing game, where you need to display several cars that look the same. Wouldn't it be a good idea to be able to send the car once through the bus, and then paint it several times without having to resend it? This functionality, which I will refer to generally as server-side techniques, is available in modern hardware, offering much improved performance over regular vertex arrays and obviously immediate mode. Server-side techniques allow us to deliver the geometry to the GPU, and store it there for a period of time. Then, each time we need to render it, we only send the render call, not the geometry, which is living in GPU memory space. This way we are rendering at the top speed the GPU can offer and are not being limited by bus bandwidth. This technique must be handled with care, though. GPU memory is limited, so its use should be kept under strict control. However, if we master this technique, we will achieve a performance gain, sometimes doubling regular performance. Server-side techniques must be supported by your graphics hardware. ATI Radeon and anything beyond GeForce2 support different rendering primitives that work from GPU memory. But most of the older hardware doesn't, so you will need to implement this as an option (or be restrictive in your hardware requirements). Additionally, different vendors and APIs expose this functionality in different ways. As an example, we can use Compiled Vertex Arrays (CVAs), which offer functionality that is similar to cache memory. Using CVAs, we can deliver geometry to the hardware and leave it there if we are going to need it again soon. Thus, subsequent calls get the geometry from the GPU, not main memory. This technique is very useful in instance-based scenarios, such as the car racing game mentioned earlier. You specify the primitive once, and from that moment on, it is "cached" on the GPU. As an extreme case, imagine the Yosemite resolution example mentioned in a previous section. In these cases, it makes no sense to have all trees modeled individually. Rather, you would do a few different instances, and by combining them randomly, get the overall feeling of a forest. Then, using CVAs can greatly speed up the rendering of the trees because many of them would really be the same core geometry primitive. Extending this concept, we could think of GPU memory as a fast cache, which we can freely access and manage. We could write models to it, delete them, and send them down the rendering pipeline efficiently. The main advantage to CVAs would be complete control over the memory, which would become similar in functionality to system memory. This new primitive is available on newer cards (GeForce2 GTS and later, ATI Radeon) and on both OpenGL (as an extension) and DirectX 8. The sad news is that cards implement this functionality under proprietary standards, so you need to code differently depending on the hardware you are running. Under OpenGL, NVIDIA cards expose this as the Vertex_Array_Range (VAR) extension, whereas ATI uses Vertex_Array_Objects. Although both are essentially the same, coding is card specific, which is a burden on the programmer. Under DirectX 8, all these functions and alternatives are encapsulated in the VertexBuffer interface for easier access. All we need to do is mark the vertex buffer as write-only, so the API knows it can be delivered and cached in the graphics card for effiecient rendering. Having complete access to GPU memory offers the programmer top flexibility and performance. Models that are used frequently or that require instancing can be stored in GPU memory and will be rendered without bus speed constraints. There are, however, limitations to these techniques. Primarily, they are designed for static data only. If you need to display an animated character, it makes no sense to store it persistently in GPU memory. The same applies to procedural geometry, or simply geometry that goes through a triangle reduction routine on a frame-by-frame basis. GPU memory is slow to access, so performance with dynamic geometry is comparatively low. |
|
|
Ajax Editor
JavaScript Editor