Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Data Structures for Outdoors RenderingWe will begin our journey by examining the different ways commonly used to store the outdoors rendering data. We must begin by distinguishing the different elements. The data used to represent terrain is what will concern us most. We have already explored ways to deal with regular objects that you can use to store objects laid on top of the land—like a building, for example. You can find more on that in Chapter 12, "3D Pipeline Overview." Some interesting approaches to this problem that are well suited for outdoors scenarios (namely, a continuous LOD policy called progressive meshes) are discussed in Chapter 22, "Geometrical Algorithms." If you need information on trees and vegetation, look no further than Chapter 20, "Organic Rendering." We will now focus on storing land masses, which is an interesting and difficult problem in its own right. First, we will need to store large data sets. Second, we will need some kind of LOD policy to make sure we don't spend lots of triangles painting very distant areas. Third, this policy must be smooth enough so we can progressively approach a new terrain region and switch from the low-res version to the high-res version imperceptibly. This makes terrain rendering algorithms somewhat more specialized and complex than most of their indoors counterparts. HeightfieldsThe easiest way to store terrain is to use a grayscale bitmap that encodes the height of each sampled point at regular distances. Traditionally, dark values (thus, closer to zero) represent low height areas, and white values encode peaks. But because bitmaps have a fixed size and color precision, you need to define the real scale of the map in X, Y, and Z so it can be expanded to its actual size. For example, a 256x256 bitmap with 256 levels of gray can be converted into a landmass of 1x1 kms and 512 meters of height variation by supplying a scale factor of (4,4,2). Heightfields are the starting point for many terrain renderers. They can be handled directly and converted to quadtrees, and they provide a simple yet elegant way of specifying the look of the terrain. You can even create these bitmaps with most paint programs or with specific tools such as Bryce, which creates very realistic terrain maps using fractal models. Once created, heightfields can be stored in memory either directly as an array of height values or in uncompressed form, with each value expanded to its corresponding 3D point. The first option is usually preferred because the memory footprint is really low, and expansion is not that costly anyway. Additionally, painting a heightfield is usually achieved through triangle strips, indexed primitives, or a combination of both. A landmass is really just a grid with the Y values shifted vertically, and grids are very well suited for strips and indices (see Figure 14.1). Figure 14.1. Terrain and underlying heightfield.
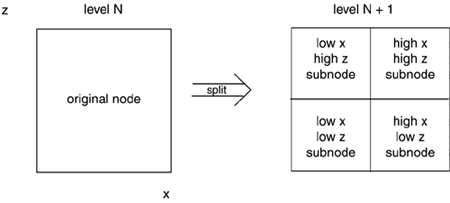
The downside of the simplicity and elegance of heightfields is that they are limited to 2D and half maps. Obviously, for a fixed X,Z pair there is only one pixel value on the heightfield, so it is impossible to implement an arch or an overhang using this representation. These elements must be handled in a second layer added on top of the base terrain. Additionally, heightfields are not especially well suited for LOD modeling. Thus, they are frequently used only in the first stage, deriving a better-suited structure from them. Most popular algorithms, such as the geomipmapping and Real-time Optimally Adapting Meshes (ROAM), use heightfields as a starting point. However, other data structures such as quadtrees and binary triangle trees are used when it comes to LOD processing. QuadtreesAnother way of storing terrain is to use a quadtree data structure. Quadtrees are 4-ary trees that subdivide each node into four subnodes that correspond to the four subquadrants of the initial node. Thus, for a terrain mass lying in the X, Z plane, the quadtree would refine each node by computing its midpoint in X and Z and creating four subnodes that correspond to the (low X, low Z), (low X, high Z), (high X, low Z), and (high X, high Z). Figure 14.2 will help you to better picture this splitting. Figure 14.2. Node splitting on a quadtree.
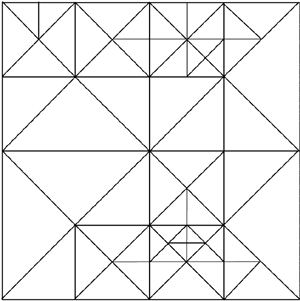
Quadtrees are popular for terrain representation because they provide a twofold adaptive method. The construction of the quadtree can be adaptive in itself. Starting with a heightfield, you can build a quadtree that expands nodes only when more detail is needed. The resulting quadtree will be a 4-ary, fully unbalanced tree, meaning that some branches will dig deeper than others. The metric for the detail level can then be of very different natures. A popular approach is to analyze the contents of the node (be it a single quad or the whole terrain landmass) and somehow estimate the detail as the variance between the real data and a quad that took its place. For each X,Z pair, we retrieve the Y from the original data set and compare it to an estimated Y, which is the bilinear interpolation of the four corner values. If we average these variances, we will obtain a global value. Larger results imply more detail (and thus a greater need to refine the quadtree), whereas smaller, even zero, values mean areas that have less detail and can thus be simplified more. But that's only one of the two adaptive mechanisms provided by a quadtree. The second mechanism operates at runtime. The renderer can choose to traverse the quadtree, selecting the maximum depth using a heuristic based upon the distance to the player and the detail in the mesh. Adding the proper continuity mechanisms to ensure the whole mesh stays well sown allows us to select a coarser representation for distant elements (for example, mountain peaks located miles away from the viewer) while ensuring maximum detail on nearby items. This double adaptiveness provides lots of room to design clever algorithms that take advantage of the two adaptive behaviors of the quadtree. Binary Triangle TreesA binary triangle tree (BTT) is a special case of binary tree that takes most of its design philosophy from quadtrees. Like quadtrees, it is an adaptive data structure that grows where more detail is present while keeping a coarser representation in less-detailed areas. Unlike quadtrees, the core geometrical primitive for a BTT is, as the name implies, the triangle. Quadtrees work with square or rectangular terrain areas, whereas BTTs start with a triangular terrain patch. In order to work with a square data set, we must use two BTTs that are connected. Because the core primitive is different from a regular quadtree, the division criteria for the BTT are different from that of quadtrees as well. Quadtrees are divided in four by the orthogonal axis at the center of the current region. A BTT triangle node is divided in two by creating two new triangles, which share an edge that splits the hypotenuse of the initial triangle in half (see Figure 14.3). Figure 14.3. Top-down view on a terrain patch scanned using a BTT.
BTTs are popular for terrain rendering because they provide an adaptive level of detail, and each node has fewer descendants and neighbors than quadtrees. This makes them easier to keep well connected in continuous LOD algorithms. The ROAM algorithm explained in a later section in this chapter takes advantage of this fact and uses a BTT to implement a continuous level-of-detail (CLOD) policy efficiently. |
|
|
Ajax Editor
JavaScript Editor