Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
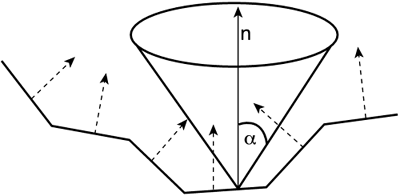
A GPU-Centric ApproachAll the algorithms we have reviewed so far share one feature in common: They all implement some kind of CLOD policy. This means that these algorithms require expensive computations, usually performed on the CPU, to generate the multiresolution mesh. Simple performance tests show algorithms like ROAM tend to be bounded not by the raw rendering speed, but by the CPU horsepower, which needs to recompute the terrain mesh frequently. In a time when CPUs are mostly devoted to AI and physics, occupying them with terrain rendering can be dangerous because it can take away precious resources needed for other areas. Besides, remember that today's GPUs have huge processing power, not just to render triangles, but to perform tests on them as well. In fact, in many cases, the GPU is underutilized because it is not fed with data properly by the application stage. Thus, I want to complete this chapter by proposing a radically different approach to terrain rendering, one where the CPU is basically idle, and all the processing takes place on the GPU. This might sound a bit aggressive, but the experience will be clarifying, at least in perspective. Our research shows such an algorithm can not only compete with traditional CPU-based approaches, but can surpass them in many cases as well. The premise of the algorithm is simple: The CPU must be idle at all times, and no data will use the bus for rendering purposes. Thus, terrain geometry will be stored directly on the GPU in a method suitable for quick rendering. The format we have selected is blocks of 17x17 vertices, totaling 512 triangles each. These blocks will be stripped and indexed to maximize performance. By using degenerate triangles, we can merge the different strips in one sector into one large strip. Thus, each terrain block consists of a single strip connecting 289 unique vertices. Assuming the index buffer is shared among all terrain blocks, we only need to store the vertices. A couple lines of math show that such a block, stored in float-type variables, takes only 3KB. A complete terrain data set of 257x257 vertices takes 700KB of GPU memory. Then, geometry blocks will be stored in the GPU and simply painted as needed. Bus overhead will thus be virtually nonexistent. The CPU will then just preprocess culling and occlusion information, and dispatch the rendering of blocks. Thus, we will begin by dividing the terrain map using a quadtree data structure, where leaf nodes are the terrain blocks. This quadtree will be in user memory, and we will use it to make decisions on what blocks need to be rendered. This way we can quickly detect the block the player is standing on and perform hierarchical clipping tests using the quadtree. We can easily integrate culling into the algorithm. For each terrain block, we compute the average of all the per-vertex normals of the vertices in the block. Because terrain is more or less continuous, normals are more or less grouped. Thus, on a second pass, we compute the cone that, having the average normal as its axis, can contain all of the remaining normals. We call this the clustered normal cone (CNC) (see Figure 14.13). We can then use the CNC to perform clustered backface culling as explained in Chapter 12. For each block, we test the visibility of the CNC and, if the cone is not visible, the whole terrain block is ignored. Notice how testing for visibility with a cone has exactly the same cost as regular culling between vectors. For two vectors, we would cull away the primitive if the dot product between the normal and the view vector was negative. For a cone, all we need to do is the dot product between the view vector and the averaged normal. Then, if the result is below the cone's aperture, we can reject the whole terrain block. Figure 14.13. The CNC, which holds information about the normals of a terrain block.
Clustered backface culling is performed on software. For a sector that is going to be totally culled away, one test (that's a dot product and a comparison) will eliminate the need to do further culling tests on each triangle. As a final enhancement, we can use our terrain blocks to precompute visibility and thus perform occlusion culling. The idea is again pretty straightforward: In a preprocess, we compute the Potentially Visible Set (PVS) for each node and store it. Thus, at render time, we use the following global algorithm:
using the quadtree, find the block the player is on
for each block in its pvs
if it can't be culled via clustered culling
if it can't be clipped
paint the block
end if
end if
end for
To precompute the PVS, we compute a bounding column (BC) for each terrain block. A BC is a volume that contains the whole terrain block but extends to infinity in the negative Y direction. Thus, the terrain will be simplified to a voxel-like approach. Once we have computed the BC, it is easy to use regular ray tracing using the boxes to precompute interblock visibility. Fire rays from points at the top of each bounding column toward surrounding cells, trying to detect if they reach them or are intersected by other geometry. An alternative method for a platform supporting occlusion queries is to use them on the BC geometry to detect whether a block is visible. Now, let's examine the results. Notice that this algorithm does not use a CLOD policy. But it performs similarly to ROAM using the same data set. The main difference is the way time is spent in the application. In ROAM, we encountered a 10–20 percent CPU load time, whereas the GPU-centric approach used only 0.01 percent. Additionally, the full version with clustered culling and occlusions outperformed ROAM by a factor of two, and occlusion detection can be very useful for other tasks like handling occlusions for other elements (houses, characters, and so on), AI, and so on. As an alternative, we have created tests on a variant that does use LODs in a way similar to the chunked LOD/skirts method explained earlier in this chapter. We store terrain blocks at four resolutions (17x17, 9x9, 5x5, 3x3 vertices) and at runtime select which one we will use, depending on the distance to the viewer and an onscreen error metric. Unsurprisingly, performance does not improve: It simply changes the cost structure. The GPU reduces its workload (which wasn't really an issue), but the CPU begins to slow the application down. The only reason why implementing LOD in the core algorithm makes sense is really to make it work on cards that are fill-rate limited. On these cards, adding LODs might improve performance even more. In this case, the algorithm would be
using the quadtree, find the block the player is on
for each block in its pvs
if it can't be culled via clustered culling
if it can't be clipped
select the LOD level for the block
paint the block
end if
end if
end for
This section is really meant to be an eye-opener for game developers. Sometimes we forget that there's more than one way to solve a problem, and this terrain rendering approach is a very good example. |
|
|
Ajax Editor
JavaScript Editor