Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
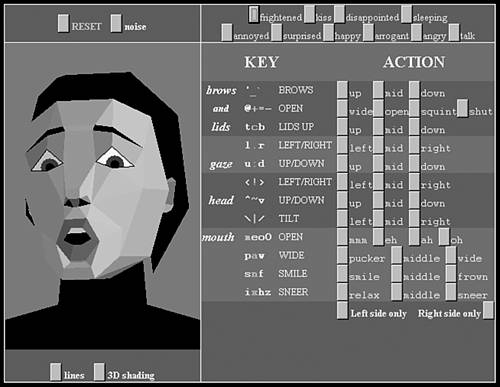
Facial AnimationMost of a character's emotion and personality are conveyed through his face: Anger, fear, and disenchantment are really hard to simulate if facial gestures are not available. Many of today's games and most games from the future will incorporate some kind of real-time facial animation. The first step is lip-synching, or the ability to move the mouth and lips so the character looks like he's actually pronouncing each word. On top of that, you can build a whole facial emotion system. Taking this to the extreme, facial animation could be integrated with a full-body animation system, so characters could express themselves through body and facial gestures. This kind of approach yields elegantly to a level-of-detail based policy. Facial expressions are only required for up-close characters because the nuances of emotion are lost at larger distances. Thus, you could code a system that performed full-body animation, and as characters moved closer to the camera, introduce facial animation and emotions as well. There are two schools of facial animation. The first one is characterized by animating the vertices directly. Computational cost is reduced, but memory footprints can grow, especially if a highly detailed face is to be animated. The second trend is to animate facial muscles using a skeletal system. The skeleton of the character simply extends to his face, so we can animate areas of the face hierarchically. This second method is CPU-intensive because many bones are required. For a character in the Sony game The Getaway, as many as 35 bones were used for the face alone. Vertex-based facial animation is popular for simple games. Vertices are clustered according to face muscles, and displacement functions are applied to convey personality. Coding such a solution is not very hard, and with some care, emotions can be layered to create complex expressions. One of the best examples of this philosophy is the facial animation demo by Ken Perlin, which can be seen in Figure 15.7 and is available from his web site at http://mrl.nyu.edu/~perlin/facedemo. Figure 15.7. Ken Perlin's facial animation demo with all the controls to set parameters to expressions.
Vertex-based systems do not scale well. As the number of expressions increases, especially if you add lip-synching to the mix, the amount of expressions to model becomes unfeasible, both in terms of man-hours and memory footprint. In these scenarios, using a skeletal animation system will yield much better results. Representation is extremely compact, and results are equally impressive. Skeletal animation, on the other hand, animates vertices using a bone hierarchy. For a face, the hierarchical component of skeletal systems will not be very useful, because these kinds of relationships do not really occur in faces. However, another characteristic of skeletal animation will indeed be very useful: the ability to influence a single vertex by more than one bone, so a vertex in the cheek gets influence from the jaw, eyes, and so on. Additionally, skeletal animation systems are great for performing selective blends—mixing a face for the brows with a different expression for the rest of the face, for example. It's all a matter of selecting which bones from which expression will be mixed. Whichever method you choose, it is fundamental to understand the structure of the face in order to achieve realistic results. In this respect, I recommend taking a look at the Facial Action Coding System proposed by Ekman and Friesen in the late 1970s. This system tries to describe facial expressions objectively, using scientific criteria. It starts by analyzing expressions in terms of the muscles used to generate them. All facial muscles affecting the look of the face were analyzed, and a thorough listing of their effect on the face was built. The list had 46 entries, which appeared by moving one single muscle or muscle group. You can then combine different muscles and their states to convey a composite expression: a different muscle configuration for the eyes, jaw, brows, and so on. To perform lip-synching, your software must be able to animate the mouth area to simulate the different phonemes, or sounds in the language the character is speaking. Each language has a different number of phonemes; English has approximately 35. Because that is such a large number (just imagine the amount of work needed to create the array of animated faces), sometimes phonemes that are pronounced similarly are simplified, so less work needs to be done. This was discovered a long time ago by Disney animators, who simplified the whole phoneme set to just 12 canonical mouth positions. Then, a facial animation system such as face morphs or skeletal animation can be used to perform the actual animation. One of the problems with such an approach is that pronunciation has a high emotional component. The same word said whispering or yelling at someone will look radically different. However, facial animation using bones looks like the way to go for the industry— similar to the way skeletal animation replaced frame-based methods progressively in the past. All that is needed are better bone layout strategies that help convey the wide range of expressions and emotions of a human face. Obviously, most bones will control either the eyes (or brows) or the mouth, because these are the main expressive elements in a face. But it's the precise layout that still needs to be mastered. |
|
|
Ajax Editor
JavaScript Editor