Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Light MappingWe have seen how per-vertex illumination results can vary in quality depending on the mesh resolution, normal vector placement, and so on. A fine mesh with good smoothing can look great with just hardware, per-vertex lights. But coarse meshes with large triangles (walls, for example) are not well suited for the technique. Adjacent vertices are too far apart, and thus the hardware takes too few samples to convey a realistic sense of lighting. To make things worse, interpolation artifacts frequently occur, especially with moving lights, completely breaking the sense of immersion. Light mapping is the global name used to describe different techniques that try to simulate pixel-correct illumination values by using textures to encode illumination properties (not only materials). Textures used to store lighting data are called light maps and can encode both diffuse and specular characteristics for any light, whatever the shape, color, and orientation. Light mapping became popular through its use in the Doom/Quake sagas, and since then has become absolutely fundamental to many games. It provides a relatively easy and effective way of creating realistically lit scenarios (see Figure 17.4). Figure 17.4. Left: base texture. Middle: additive (specular) light map. Right: result.
To understand light mapping, you must first be fully aware of texture and color arithmetic and blending, so make sure you review these concepts before moving on. We will fundamentally use texture arithmetic to implement lighting equations, so textures are blended together to produce the end result. Diffuse Light MappingThe first technique we will explore is diffuse light mapping, which uses light maps to simulate Lambert's equation of diffuse lighting. Essentially, we will try to keep materials unchanged in well-lit areas while making them darker in shady areas. If you think about this in arithmetic terms and review the diffuse portion of the lighting equation from the previous section, you will see that this situation is equivalent to a texture multiplication. The light map will be white (1,1,1) in lit zones and black in dark corners. If we paint the texture and then multiply it by the light map, a convincing diffuse shading effect will be achieved. Specular Light MappingSpecular lighting can also be simulated with light maps. Here, we try to "burn" textures due to light being emitted intensely in a certain direction. Specular lighting has a potential downside, though. Remember that the specular component is viewpoint dependent, so a viewer moving around an object should see the highlights move as well. Because we are limiting ourselves to static light mapping now, we cannot simulate this effect accurately. But imagine that the distance from the light to the lit wall is much smaller than the distance from the viewer to the wall. In this case, the dependency of specular highlights with regard to viewer movement would be very small, and therein lies the trick: Specular light mapping can accurately model highlights caused not by distant lamps illuminating highly reflective surfaces (think of a bright light and a metal ball), but by regular lights placed close to surfaces, thus producing the usual color burn. These highlights are almost viewpoint independent and look convincing when rendered with light maps. In terms of texture arithmetic, a specular light map can be considered a texture addition. We add the light to the base material, so those pixels with high specular components are highlighted. Again, the light map would encode lighting using pure white (or whatever the light color is) for specularly lit areas and black for nonspecular zones. Specular light maps must be used sparingly. The main lighting contribution in any scene is always diffuse, and specular highlights are used only as finishing touches over that base illumination layer. Global Illumination Using Light MapsWe can combine the diffuse and specular component of light maps to achieve a high-quality result, very similar to the solution proposed in the previous section. Again, it all boils down to texture arithmetic. A global illumination light map engine would use three textures, combined in the following way: Color = Material_Color * Diffuse_light_map + Specular_light_map Implementing Light Mapping: OpenGLLight maps can be implemented in OpenGL via multipass rendering or by using multitexture on capable hardware. The multipass option is somewhat slower, but code is probably easier to understand, so let's cover both. For completeness, we will cover the more complex, global illumination solution, which handles diffuse as well as specular lighting. Multipass VersionWe will implement light maps using three passes: The first will render a base object with corresponding material. Then, a second pass will multiply, simulating the diffuse component. A third pass will perform an additive blend to incorporate specular highlights. Let's look at some code, and comment it: // first pass glBindTexture(GL_TEXTURE_2D,basematerialid); glDisable(GL_BLEND); glDepthFunc(GL_LESS); // here you would render the geometry (...) // second pass: diffuse multiply glBindTexture(GL_TEXTURE_2D,diffusematerialid); glEnable(GL_BLEND); glBlendFunc(GL_DST_COLOR,GL_ZERO); glDepthFunc(GL_LEQUAL); // here you would re-send the geometry, only mapping coordinates would differ (...) // third pass: specular additive glBindTexture(GL_TEXTURE_2D,specularmaterialid); glEnable(GL_BLEND); glBlendFunc(GL_ONE,GL_ONE); glDepthFunc(GL_LEQUAL); // last geometry submission, only mapping coordinates would differ (...) It all boils down to setting the right blending mode and sending the geometry as many times as needed. Implementing Light Mapping: DirectXIn this section, I will expose the code necessary to handle light mapping under DirectX 9. The code is thoroughly commented and is actually quite straightforward. If you are not familiar with texturing stage operations, take a look at the "Texture Arithmetic" section in Chapter 18, "Texture Mapping," for more information. In this first example, we implement diffuse light mapping using only two passes: one for the base texture and a second pass used to modulate it with the lightmap. // This example assumes that d3dDevice is a valid pointer to an // IDirect3DDevice9 interface. // lptexBaseTexture is a valid pointer to a texture. // lptexDiffuseLightMap is a valid pointer to a texture that contains // RGB diffuse light map data. // Set the base texture. d3dDevice->SetTexture(0,lptexBaseTexture ); // Set the base texture operation and args. d3dDevice->SetTextureStageState(0,D3DTSS_COLOROP, D3DTOP_SELECTARG1); // first operator: the base texture d3dDevice->SetTextureStageState(0,D3DTSS_COLORARG1, D3DTA_TEXTURE ); // Set the diffuse light map. d3dDevice->SetTexture(1,lptexDiffuseLightMap ); // Set the blend stage. We want to multiply by the previous stage d3dDevice->SetTextureStageState(1, D3DTSS_COLOROP, D3DTOP_MODULATE ); // first parameter is the light map d3dDevice->SetTextureStageState(1, D3DTSS_COLORARG1, D3DTA_TEXTURE ); // second parameter is the previous stage d3dDevice->SetTextureStageState(1, D3DTSS_COLORARG2, D3DTA_CURRENT ); Now, a more involved example which handles both specular and diffuse using three stages: // This example assumes that d3dDevice is a valid pointer to an // IDirect3DDevice9 interface. // lptexBaseTexture is a valid pointer to a texture. // lptexDiffuseLightMap is a valid pointer to a texture that contains // RGB diffuse light map data. // Set the base texture. d3dDevice->SetTexture(0,lptexBaseTexture ); // Set the base texture operation and args. d3dDevice->SetTextureStageState(0,D3DTSS_COLOROP, D3DTOP_SELECTARG1); // first operator: the base texture d3dDevice->SetTextureStageState(0,D3DTSS_COLORARG1, D3DTA_TEXTURE ); // Set the diffuse light map. d3dDevice->SetTexture(1,lptexDiffuseLightMap ); // Set the blend stage. We want to multiply by the previous stage d3dDevice->SetTextureStageState(1, D3DTSS_COLOROP, D3DTOP_MODULATE ); // first parameter is the light map d3dDevice->SetTextureStageState(1, D3DTSS_COLORARG1, D3DTA_TEXTURE ); // second parameter is the previous stage d3dDevice->SetTextureStageState(1, D3DTSS_COLORARG2, D3DTA_CURRENT ); // Set the specular light map. d3dDevice->SetTexture(2,lptexDiffuseLightMap ); // Set the blend stage. We want to add by the previous stage d3dDevice->SetTextureStageState(2, D3DTSS_COLOROP, D3DTOP_ADD ); // first parameter is the light map d3dDevice->SetTextureStageState(2, D3DTSS_COLORARG1, D3DTA_TEXTURE ); // second parameter is the previous stage d3dDevice->SetTextureStageState(2, D3DTSS_COLORARG2, D3DTA_CURRENT ); As you can see, neither of them is complex: It is all a matter of knowing the math behind lightmapping and expressing it correctly in your API of choice. Creating Light MapsLight maps can be created in a variety of ways. A first, naïve approximation would be to paint them by hand. This can be achieved with any image processing software such as Adobe Photoshop, and depending on the artist's talent, can produce strikingly good results. But it is a time-consuming process, and getting right the subtle interaction of light on surfaces is sometimes easier said than done. Some illumination effects are pretty unpredictable, and an artist might fail to convey the complexity of real-world lighting. A second alternative is to compute them with the aid of rendering packages. Most rendering packages can help us, with varying degrees of success, in the process of creating light maps. However, most of them will require post-processing because they seldom offer a "cradle-to-grave" light map creation option. Thus, a third and quite popular alternative is to compute these maps with proprietary tools, which perform complete lighting analysis, compute textures, and store them in a suitable format. Many software packages can help you compute light maps. Commercial renderers can create images seen from light sources, so you can reuse this shadow map. Radiosity processors can analyze lighting in a scene and output the information per vertex, and in some cases, even produce the required light maps. Sometimes, it is even coupled with a radiosity preprocess to ensure that lighting data is true to life. Light Map Computation: PhongThe first and simplest way of computing light maps is to simply evaluate the diffuse and specular components of lighting by taking lights into consideration, but forgetting about occluders and shadows. The process is relatively straightforward and will lead the way to the more involved solutions exposed in the following sections. To keep things even simpler, let's forget about light map packing for a second and focus on creating the light map for a single quad, lit by several colored light sources. The first decision to make is the light map size. As you will soon see, this size determines not only the quality of the results, but also the memory footprint of our application. Light maps are usually low resolution because they represent lighting gradients. Thus, when magnified, interpolation does not produce visual artifacts, but instead helps smooth out the lighting. Another issue to watch out for when selecting the right size is that to achieve realistic results, all light maps should be more or less of the same scale: A larger quad will require a larger light map, and so on. Thus, it is useful to think about light maps in terms of world-space size. For example, what sampling frequency do you want to establish in world units? Will one lumel (the equivalent to a pixel on a light map) correspond to one centimeter, 10 centimeters, or half a kilometer? For our simple example, let's assume our quad is a square 1x1 meter. We will use a 64x64 light map, so lighting will have a resolution of 1.5 centimeters per sample approximately. Once light map resolution has been set, we need to compute the coordinates of each sampling point, so we can then illuminate it. The sampling point computation for a quad is a simple bilinear interpolation, which divides the quad in a tile as fine as the light map size. Here is the code to compute light map coordinates (in 3D space) for lumel (lu,lv):
point Create3Dpoint(float lu,float lv)
{
// interpolate along the U axis
point v1=p2-p1;
point v2=p3-p4;
point v1=p1 + v1*(lu/LIGHTMAPSIZEU) ;
point v2=p4 + v2*(lu/LIGHTMAPSIZEU) ;
// interpolate along the V axis
point w1=v2-v1;
point w2=v1+w1*(lv/LIGHTMAPSIZEV);
return w2;
}
Now we have a 3D point we want to compute illumination for. But this is the easy part, because we discussed the classic ambient-diffuse-specular illumination equation earlier in the chapter. Now, it is all a matter of looping through the scene lamps, computing their contribution to the lighting of the lumel we are working on. All in all, computing a single light map affected by a number of lights is a O(n^3) process. We need to loop through a bidimensional array of lumels, each one affected by several lights. Keeping in mind that this is just the simplest (and fastest) light map computation process, you will understand why light maps are usually created in a preprocess, often taking several minutes to complete. In summary, here is the pseudocode for a light map processor that handles a complete scene. For simplicity, I have assumed each light map is stored in a different texture map. We will cover light map packing in the section "Storing Light Maps."
for each primitive in the scene
compute the ideal light map size
for each position in the light map along the u axis
for each position in the light map along the v axis
un-project U,V to 3D coordinates
initialize the lighting contribution to 0
for each lamp in the scene
add the influence of the lamp to the overall contribution
end for
store the lighting contribution to the light map
end for
end for
store the light map
end for
Notice that, depending on how you compute lighting, you can generate diffuse-only, specular-only, or both specular and diffuse light maps using the preceding algorithm. It all depends on how you implement the lighting equation. However, some effects will not be rendered correctly. Shadows, for example, will not be accounted for. We will need a more involved algorithm to increase the realism. Light Map Computation: Ray TracingWe can produce better looking results by introducing ray tracing techniques into the preceding algorithm. The core algorithm will stay the same, but before considering the contribution of a given lamp to a lumel, we will fire a shadow ray from the lumel to the lamp and test for intersections with the rest of the scene. This way we can handle shadows for much increased realism. Notice how we won't be using recursive ray tracing, which is reserved for reflections and transparencies. A single shadow ray from the lumel to the light will tell us if the lumel should be lit by the lamp or if it stays in the shade. Thus, the main addition to the previous algorithm is both the construction of the shadow ray and the shadow ray-scene intersection test. The construction is very simple: Rays are usually represented by an origin (in our case, the lumel being lit) and a unit direction vector: ray.origin=lumel; ray.direction=lamp.pos – lumel ; ray.direction.normalize() ; Now, computing ray-scene intersection tests is a different problem (sadly, a more complex one). Efficient ray-triangle set tests are hard to find. I will expose the simplest test (which is incidentally the slowest one) and also a very efficient test, which will yield near-optimal results. In a simple scene, the easiest way to compute the intersection between a ray and a triangle set is to examine triangles one by one and triangle-test each one. If any of the triangles effectively intersects the ray, our lumel is in shadows. The ray-triangle test is as follows:
You can make an early rejection test by making sure the ray's origin effectively lies in front of each triangle you test (using the triangle's normal). Only visible (nonculled) triangles can actually cause a point in a level to be in shadows. This algorithm runs at O(number of triangles in the scene). Now, because light map processors are usually run offline, this high cost might not be a problem. But remember to keep an eye on your total computational cost. Ray tracing is an intensive algorithm, and processing times can skyrocket if you are not careful. As a sampler, here is the composite cost of a light map processor using ray tracing with this intersection test: O(number of triangles * lightmap U size * lightmap V size * ( number of lights * number Notice how the cost in the inner parentheses is for the ray tracing pass. Each lumel must shoot a ray to each lamp, and this ray needs to be tested against all level geometry—all in all, O(n^5). Now, we can use a better ray-triangle intersection test to help reduce processing times. The one we will use takes advantage of visibility computation. By knowing which areas of the level are visible from a given lumel, we can reduce the potential lamp and occluder set. Imagine, for example, that you are working with a portal approach. Then, given a lumel (in 3D coordinates), you can compute which cells are visible from that point. Because we are only considering direct lighting, only lamps in visible cells can potentially illuminate the lumel, so we can begin by eliminating all the others as candidates. A second improvement appears in the ray-triangle intersection test. For a triangle to shadow the lumel, the triangle must lie in one of the visible cells as well. If a triangle is not in the Potentially Visible Set (PVS) of the lumel, how can it shadow the lumel? Thus, a better light mapping processing algorithm can be built. Here is the pseudocode for this algorithm:
for each primitive in the scene
compute the ideal light map size
for each position in the light map along the u axis
for each position in the light map along the v axis
un-project U,V to 3D coordinates
initialize the lighting contribution to 0
compute the potentially visible cells from the lumel
for each lamp in the visible set
compute a shadow ray from lumel to lamp
for each triangle in the visible set
test for intersections between ray and triangle
end for
if no intersections occurred
add the lamp influence to the global contribution
end if
end for
store the lighting contribution to the light map
end for
end for
store the light map
end for
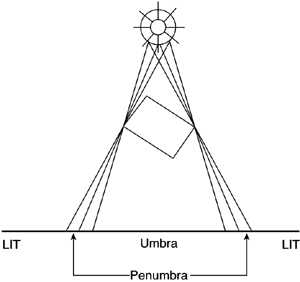
Note how this new version is much more efficient than using brute-force ray-triangle intersections. In large levels with high triangle (and lamp) counts, the difference between using brute-force ray tracing and this new, accelerated method would be of orders of magnitude, given the intensive nature of ray tracing approaches. As a final note, you can also speed up the ray-triangle test directly if you can't count on a visibility structure. Many methods have been devised through the years—the most efficient probably being Fujimoto's algorithm. This method, along with intersection tests for spheres and boxes, is explained fully in Chapter 20, "Organic Rendering." Advanced Light Maps Using Ray TracingMore powerful ray tracing techniques can be used to compute complex light mapping effects. In this section, I will provide a listing of effects and suitable techniques. Penumbras, for example, can easily be added to the ray tracing pass by using Stochastic (Monte-Carlo) ray tracing. Here we extend the shadow ray to a group of rays, which are directed in a Poisson distribution toward the light source (which in turn needs to become an area light) in a cone. Each ray is then tested with the scene for occlusions. By sampling the whole lighting area, shadows are no longer binary, but can offer subtle gradations (see Figure 17.5). Stochastic ray tracing is significantly slower than the classic algorithm, but results have heightened quality. Also, we can again use visibility techniques to speed up the process. We will only fire several rays toward those lamps that, being visible from the lumel, have an area. Figure 17.5. Umbras and penumbras.
A variant of ray tracing called photon mapping can be used to precompute light concentration phenomena or caustics. Here, a preprocess fires a number of rays from the different light sources (usually, several hundred thousand) and makes them bounce off the different surfaces. Whenever a lumel is hit by a ray, we increase a counter. So at the end of this preprocess, we can see if a lumel received lots of illumination or if it remained in the shade. If we consider semitransparent objects using Snell's law, light concentration phenomena will take place, and thus will be incorporated into the light maps. But do not overestimate light maps. Because we are computing them as a preprocess, shadows won't animate as lights move, and caustics made by a swimming pool will remain motionless. Light Map Computation: RadiosityAn alternative to ray tracing, and probably the method that delivers the best results, is using a radiosity processor to compute light maps. Radiosity is a lighting analysis algorithm based in real physics, with each surface element acting as both an absorbent of incoming light and a reflector. Thus, radiosity can accurately compute how light reacts in a scene, where it concentrates, and where shadows appear. The radiosity algorithm is quite involved. Thus, many companies use commercial software to compute a solution for the problem. If you want to code your own, this section provides you with an overview. Radiosity tries to compute global lighting in terms of energy transfer between the different surfaces in the scene. It starts by dividing the scene into patches and assigning two values to each: the illumination value (which represents how much light it is receiving from other patches) and the radiative energy (the amount of energy at the patch). As you probably know, there are no light sources in radiosity. A light source is nothing but a patch with radiative energy. Now, we need to compute the energy transfer from each pair of surfaces, which is a O(n2) problem. We take each patch and compute a factor that depends on the distance, shape, and orientation, and represents how much energy can be transferred from one patch to the other. This factor is known as the form factor. Form factors are laid out in an NxN matrix, which represents all the relationships between patches. Then, to compute the energy transfer, we scan the matrix looking for patches with radiative energy. When we find one, we transfer part of that energy to other patches by means of the form factors, thus executing one step in the illumination process. We then start over, analyzing again which matrix positions still hold radiative energy. In this second wave, we will consider both the initial emitters and the emitters that received energy in the previous step, which became secondary emitters. This process is iterated until the energy transfer is below a threshold, and we can say the solution is stable. There are a number of issues concerning this approach. The matrix can become large, especially if we want a pixel-accurate solution. A 1,000-triangle level needs a 1,000x1,000 matrix, assuming one triangle needs one patch exactly. That's rarely the case, because we will need more resolution and will subdivide triangles to compute finer results. The solution to this problem comes from progressive refinement, an improvement over the base radiosity algorithm proposed by Cohen, Chen, Wallace, and Greenberg in 1988. In progressive refinement, we no longer use a radiosity matrix to compute the solution. Instead, we compute the solution surface by surface. We scan the surface list and select the surface with the most radiative energy to contribute to the scene. Then, we "shoot" that energy and propagate it to the scene using form factors. This results in a redistribution of energy in the rest of the patches. We then select the surface with the most radiative energy. The original surface may be on the candidate list, but not with the same amount of energy: That energy was already shot. So, we select the new radiator and iterate the process. The algorithm stops whenever the next biggest radiator has an energy level below a threshold, and thus we can assume its contribution to the final solution is minimal. As you can see, we haven't spoken about matrices at all. All we need to store for progressive refinement to work is the energy level of all surfaces at a given moment. Here's the algorithm:
repeat
select the surface i with highest radiative energy
store its radiative energy
calculate form factors from i to all other surfaces j Fij
for each surface j
update illumination based on Fij and radiosity of i
update radiative energy based on Fij and radiosity of I
end for
set emission of i to zero
until the radiative energy of the selected surface < threshold
Another advantage of progressive refinement is that an observer can very well oversee the solution building process. It would start with a black screen, and as energy is radiated, the scene would be illuminated. This allows for the rapid rejection of scenes whose solution is not looking good and for previewing the results. Another popular issue concerning radiosity is how form factors are computed. A number of solutions have been proposed, from ray tracing and computing the percentage of rays that reach the destination surface to analytical solutions and texture-based approaches. The formal definition is as follows:
Fij= (cos qI cos qj) / (pi*r2) * Hij dAj
In this equation, the cosines represent the angular difference between both patches. To compute them, we just have to:
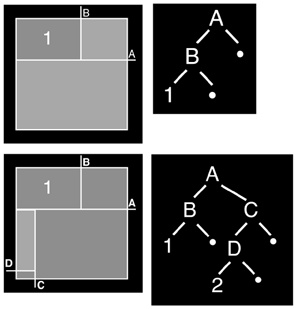
Then, we divide the result by Pi*r2 to account for distance between patches. Farther patches should have smaller form factors because the probability of light from one reaching the other diminishes. The Pi factor is needed to account for the hemispherical nature of the emitted energy. The transmitting patch shoots out energy in a hemispherical distribution, not in a single direction, and the Pi factor incorporates that into the form factor. The H function represents the visibility from patch i to patch j. How do we handle occluders? We need the form factor to incorporate any potential occlusions, so two patches with large form factors with a wall in between do not transmit energy to each other. H is just a visibility factor that scales the result from 0 to 1 depending on how much of a patch is visible from the other. The name H comes from the visibility algorithm used by many radiosity processors, which is the hemicube algorithm. Place a hemicube right above the patch in consideration and discretize it. Then, analyze the visibility on a cell-by-cell basis and store the fraction of visible cells in the H parameter. Other popular approaches involve shooting rays using a nonrecursive ray tracing approach and storing the fraction of the rays that actually hit the opposite patch. The dAj parameter is used to express the form factor in terms of differential areas. The form factor is defined per infinitesimal area element of the receiving patch, so should we want to compute it for the whole path, we would need to multiply it by the patch's area. With this explanation of how radiosity works, let's examine how we can build light maps based on radiosity. Basically, we would need a fine representation of the level geometry, where each light map texel represents one sampling point in our radiosity processor. We would start with the level geometry, setting the detail level we want to work with. Will one texel in the light map represent one centimeter or one meter? From this first analysis, light maps of the proper size must be allocated. Then, each texel in each light map can be used to trigger a radiosity processing loop. Prior to that, we need to set which patches will be radiative, so our scene has some lighting information. This is usually embedded in the content creation tools. Then, we must perform the radiosity algorithm. Progressive refinement here is the best option because the radiosity matrix for any decent-size level can become unmanageable. Imagine that your game level consists of 10,000 triangles (not uncommon for Quake-style shooters), but due to the light map resolution, that is converted into 2,560,000 patches (on average, each light map being 16x16 texels in size). Because the radiosity matrix is NxN, be prepared to handle a 2Mx2M matrix! Then, the progressive refinement algorithm would work on a set of textures that encode both the illumination (which is part of the final solution) and the radiative energy, which is what we will try to minimize by iterating the process. Visibility can be computed in many ways, some of them assisted by the use of the engine's own scene graph, whether it's a Binary Space Partition (BSP) or some kind of portal engine. Computing Hij is one of the main bottlenecks in any radiosity processor. Storing Light MapsUsing only one light map might be fine for small demos, but as soon as you want to illuminate a complete game level the need to store large numbers of light maps arises. After all, each wall and detail has unique lighting properties, so the amount of light maps must be correlated to the amount of geometry in the game level. But this might become a big issue as texture requirements grow: How many light maps are we going to store? What size will each one be? These and other questions have troubled graphics engine programmers for years, and luckily some clever solutions have been found. To begin with, light maps are usually very low resolution textures, often just a few pixels across. Sizes of 16x16, for example, are not uncommon. The reason for this resolution comes from texture filtering: The graphics card will interpolate between the different texels anyway, so a small light map can stretch over a relatively large level patch. Sharp shadows and abrupt changes of illumination will only be possible if larger light maps are used. But for the classic radiosity-like rooms with a large diffuse lighting contribution, low-res maps should be perfect. Another interesting decision is to pack several light maps in a composite, unique global texture that encapsulates them. Think about it for a second: If each light map spans across one or two triangles only, we will end up with hundreds of small textures, and we will need to swap the active texture all the time. Remember that texture swaps are costly. Thus, it is very common to store many light maps in a large map, so we can render them all with a single call. However, this otherwise great idea has a potential downside: finding an algorithm that can automatically pack light maps optimally. Doesn't sound like a big problem, right? Unfortunately, evil lurks from unforeseen corners, and packing light maps on a larger texture might be much harder than you might think. In fact, it's an instance of a classic computational problem called "set packing": placing N objects, each one with a different shape, inside a container to find the distribution that allows better space allocation. This problem is very well known, and studies demonstrate that it is an NP-Hard problem. NP-Hard problems (such as set packing of the traveling salesman) are problems so complex, no algorithm designed to work in polynomial time can solve them. Thus, we must revert to exponential approaches, which is the "elegant" way to designate brute-force approaches. In our light map example, we would need to test all possible configurations in order to find the optimal one. And, with hundreds if not thousands of light maps, exponential algorithms can take quite a while to compute. So some heuristic algorithms have been devised. These algorithms are far from optimal, so the solutions won't be perfect. But they run in reasonable times. Now I will explain one of these algorithms, which combines speed with fairly good results. The idea is pretty simple: Allocate light maps one by one, building a binary tree along the way. We will use the tree to specify occupied and free zones until all light maps have been inserted. Then, for each light map, we use the region of the tree where it can be fitted better. Every time we place a new light map, we split new nodes so the tree expands and keeps track of all light maps. For example, take a look at the progression shown in Figure 17.6, and the end result in Figure 17.7. Figure 17.6. Top: first pass, one texture inserted. Bottom: two textures into the package.
Figure 17.7. Composite light map computed by our simple packing algorithm.
And here is the source code for the complete algorithm:
class node
{
node* child[2]
rectangle rc;
int imageID;
}
node *node::insert(lightmap img)
{
if we're not a leaf then
{
(try inserting into first child)
newNode = child[0]->insert( img )
if newNode != NULL return newNode;
(no room, insert into second)
return child[1]->Insert( img )
}
else
{
(if there's already a lightmap here, return)
if imageID != NULL return NULL
(if we're too small, return)
if img doesn't fit in pnode->rect return NULL
(if we're just right, accept)
if img fits perfectly in pnode->rect
return pnode
(otherwise, gotta split this node and create some kids)
pnode->child[0] = new Node
pnode->child[1] = new Node
(decide which way to split)
dw = rc.width - img.width
dh = rc.height - img.height
if dw > dh then
child[0]->rect = Rectangle(rc.left, rc.top,
rc.left+width-1, rc.bottom)
child[1]->rect = Rectangle(rc.left+width, rc.top,
rc.right, rc.bottom)
else
child[0]->rect = Rectangle(rc.left, rc.top,
rc.right, rc.top+height-1)
child[1]->rect = Rectangle(rc.left, rc.top+height,
rc.right, rc.bottom)
(insert into first child we created)
return Insert( img, pnode->child[0] )
}
}
In Figure 17.7, the results for such an approach occupy space in a very efficient way. Cost is O(n*log n), because we need n insertions, each one taking logarithmic access time. |
|
|
Ajax Editor
JavaScript Editor