Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Optimization TheoryNo other programming has the kind of performance requirements that games do. Video games have always pushed the limits of hardware and software and will continue to do so. Enough is never enough. Game programmers always want to add more creatures, effects, and sounds, better AI, and so on. Hence, optimization is of utmost importance. In this section, I'm going to cover some optimization techniques to get you started. If you have further interest, there are a number of good books on the subject, such as Inner Loops by Rick Booth, published by Addison Wesley; Zen of Code Optimization by Mike Abrash, published by Coriolis Group; and Pentium Processor Optimization by Mike Schmit, published by AP Press. Using Your HeadThe first key to writing optimized code is understanding the compiler, the data types, and how your C/C++ is finally transformed into executable machine language. The idea is to use simple programming and simple data structures. The more complex and contrived your code is, the harder it will be for the compiler to convert it into machine code, and thus the slower it will execute (in most cases). Here are some basic rules to keep in mind:
Mathematical TricksBecause a great deal of game programming is mathematical in nature, it pays to know better ways to perform math functions. There are a number of general tricks and methods that you can use to speed things up:
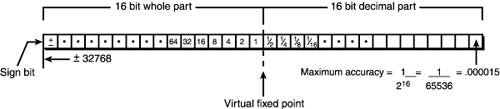
Fixed-Point MathA couple of years ago, most 3D engines used fixed-point mathematics for much of the transformation and mathematical operations in 3D. This was due to the fact that the floating-point support wasn't as fast as the integer support, even on the Pentium. However, these days the Pentium II, III, and Katmai have much better floating-point capabilities, and fixed-point is no longer as important. However, in many cases the conversion from floating-point to integers for rasterization still is slow, so sometimes it's still a good idea to try fixed-point in inner loops that use addition and subtraction operations. These operations are still faster than floating-point operations on the lower-level Pentiums, and you can use tricks to quickly extract the integral part of a fixed-point number rather than making a conversion from float to int, as you would if you stuck to floating-point. In any case, this is all very iffy, and using floating-point for everything is usually the best way to do things these days. But it doesn't hurt to know a little about fixed-point math. My philosophy is to use floating-point for all data representations and transformations, and then to try both floating- and fixed-point algorithms for low-level polygon rasterization to see which is fastest. Of course, this is even more irrelevant if you're using pure hardware acceleration. If so, just stick to floating-point all the way. With all that in mind, let's take a look at fixed-point representations. Representing Fixed-Point NumbersAll fixed-point math really is based on scaled integers. For example, let's say that you want to represent the number 10.5 with an integer. You can't; there isn't a decimal place. You could truncate the number to 10.0 or round it to 11.0, but 10.5 isn't an integer. But what if you scale the number by 10? Then 10.5 becomes 105.0, which is an integer. This is the basis of fixed-point. You scale numbers by some factor and that make sure to take this scale into consideration when doing mathematics. Because computers are binary, most game programmers like to use 32-bit integers, or ints, to represent fixed-point numbers in a 16.16 format. Take a look at Figure 11.12 to see this graphically. Figure 11.12. A 16.16 fixed-point representation.
You put the whole part in the upper 16 bits and the decimal part in the lower 16 bits. Hence, you're scaling all numbers by 216, or 65,536. Moreover, to extract the integer portion of a fixed-point number, you shift and mask the upper 16 bits, and to get to the decimal portion, you shift and mask the lower 16 bits. Here's some working types for fixed-point math: #define FP_SHIFT 16 // shifts to produce a fixed-point number #define FP_SCALE 65536 // scaling factor typedef int FIXPOINT; Conversions to and from Fixed-PointThere are two types of numbers you need to convert to fixed-point: integers and floating-point numbers. You must consider each one differently. For integers, the binary representation is in straight 2's complement, so you can use shifts to multiply the number and convert it to fixed-point. On the other hand, floats use a IEEE format, which has a mantissa and an exponent stored in those four bytes, so shifting will destroy the number. You must use standard floating-point multiplication to make the conversion. MATH 2's complement is a method of representing binary integers so that both positive and negative numbers can be represented and mathematical operations are closed on the set—that is, they work! The 2's complement of a binary number means computing by inverting the bits and adding 1. Mathematically, let's say you want to find the 2's complement of 6—that is, –6. It would be –6+1 or ~0110 + 0001 = 1001 + 0001 = 1010, which is 10 in normal binary but –6 in 2's complement. Here's a macro that converts an integer to fixed-point: #define INT_TO_FIXP(n) (FIXPOINT((n << FP_SHIFT))) For example: FIXPOINT speed = INT_TO_FIXP(100); And here's a macro to convert floating-point numbers to fixed-point: #define FLOAT_TO_FIXP(n) (FIXPOINT((float)n * FP_SCALE)) For example: FIXPOINT speed = FLOAT_TO_FIXP(100.5); Extracting a fixed-point number is simple too. Here's a macro to get the integral portion in the upper 16 bits: #define FIXP_INT_PART(n) (n >> 16) And to get the decimal portion in the lower 16 bits, you simply need to mask the integral part: #define FIXP_DEC_PART(n) (n & 0x0000ffff) Of course, if you're smart, you might forget the conversions and just use pointers that are SHORTs to access the upper and lower parts instantly, like this: FIXPOINT fp; short *integral_part = &(fp+2), *decimal_part = &fp; The pointers integral_part and decimal_part always point to the 16 bits that you want. AccuracyA question should be popping up in your head right now: "What the heck does the decimal part mean?" Well, usually you won't need it; it's just there to be used in the computations. Normally, you just want the whole part in a rasterization loop or something, but because you're in base 2, the decimal part is just a base 2 decimal, as shown in Figure 11.12. For example, the numbers 1001.0001 is 9 + 0*1/2 + 0*1/4 + 0*1/8 + 1*1/16 = 9.0625 This brings us to the concept of accuracy. With four digits of base 2, you're only accurate to about 1.5 decimals base 10 digits, or +-.0625. With 16 digits, you're accurate to 1/216 = 1/65536 = .000015258, or about one part in 10,000. That's not bad and will suffice for most purposes. On the other hand, you only have 16 bits to hold the integer part, meaning that you can hold signed integers -32767 to +32768 (or non-signed up to 65535). This might be an issue in a large universe or numerical space, so watch out for overflow! Addition and SubtractionAddition and subtraction of fixed-point numbers is trivial. You can use the standard + and – operators:
FIXPOINT f1 = FLOAT_TO_FIX(10.5),
f2 = FLOAT_TO_FIX(-2.6),
f3 = 0; // zero is 0 no matter what baby
// to add them
f3 = f1 + f2;
// to subtract them
f3 = f1 – f2;
NOTE You can work with both positive and negative numbers without a problem because the underlying representation is 2's complement. Multiplication and DivisionMultiplication and division are a little more complex than addition and subtraction. The problem is that the fixed-point numbers are scaled; when you multiply them, you not only multiply the fixed-point numbers but also the scaling factors. Take a look: f1 = n1 * scale f2 = n2 * scale f3 = f1 * f2 = (n1 * scale) * (n2 * scale) = n1*n2*scale2 See the extra factor of scale? To remedy this, you need to divide or shift out the one factor of scale^2. Hence, here's how to multiply two fixed-point numbers: f3 = ((f1 * f2) >> FP_SHIFT); Division of fixed-point numbers has the same scaling problem as multiplication, but in the opposite sense. Take a look at this math: f1 = n1 * scale f2 = n2 * scale Given this, then f3 = f1/f2 = (n1*scale) / (n2*scale) = n1/n2 // no scale! Note that you've lost the scale factor and thus turned the quotient into a non-fixed-point number. This is useful in some cases, but to maintain the fixed-point property, you must prescale the numerator like this: f3 = (f1 << FP_SHIFT) / f2; WARNING The problem with both multiplication and division is overflow and underflow. In the case of multiplication, the result might be 64-bit in the worst case. Similarly, in the case of division, the upper 16 bits of the numerator are always lost, leaving only the decimal portion. The solution? Use a 24.8-bit format or use full 64-bit math. This can be accomplished with assembly language because the Pentium+ processors support 64-bit math. Or, you can alter the format a little and use 24.8. This will allow multiplication and division to work better because you won't lose everything all the time, but your accuracy will fall apart. For an example of fixed-point mathematics, try DEMO11_4.CPP|EXE. It allows you to enter two decimal numbers and then perform fixed-point operations on them and view the results. Pay attention to how multiplication and division seem not to work at all. This is a result of using 16.16 format without 64-bit math. To fix this, you can recompile the program to use 24.8 format rather than 16.16. The conditional compilation is controlled by two #defines at the top of the code: // #define FIXPOINT16_16 // #define FIXPOINT24_8 Uncomment the one you want to use and the compiler will do the rest. Finally, this is a console application, so like Spike says, do the right thing… Unrolling the LoopThe next optimization trick is loop unrolling. This used to be one of the best optimizations back in the 8/16-bit days, but today it can backfire on you. Unrolling the loop means taking apart a loop that iterates some number of times and manually coding each line. Here's an example:
// loop before unrolling
for (int index=0; index<8; index++)
{
// do work
sum+=data[index];
} // end for index
The problem with this loop is that the work section takes less time than the loop does for the increment, comparison, and jump. Hence, the loop code itself doubles or triples the amount of time the code takes! You can unroll the loop like this: // the unrolled version sum+=data[0]; sum+=data[1]; sum+=data[2]; sum+=data[3]; sum+=data[4]; sum+=data[5]; sum+=data[6]; sum+=data[7]; This is much better. There are two caveats:
Look-Up TablesThis is my personal favorite optimization. Look-up tables are precomputed values of some computation that you know you'll perform during run-time. You simply compute all possible values at startup and then run the game. For example, say you needed the sine and cosine of the angles from 0–359 degrees. Computing them using sin() and cos() would kill you if you used the floating-point processor, but with a look-up table your code will be able to compute sin() or cos() in a few cycles because it's just a look-up. Here's an example:
// storage for look up tables
float SIN_LOOK[360];
float COS_LOOK[360];
// create look-up table
for (int angle=0; angle < 360; angle++)
{
// convert angle to radians since math library uses
// rads instead of degrees
// remember there are 2*pi rads in 360 degrees
float rad_angle = angle * (3.14159/180);
// fill in next entries in look-up tables
SIN_LOOK[angle] = sin(rad_angle);
COS_LOOK[angle] = cos(rad_angle);
} // end for angle
As an example of using the look-up table, here's the code to draw a circle of radius 10:
for (int ang = 0; ang<360; ang++)
{
// compute the next point on circle
x_pos = 10*COS_LOOK[ang];
y_pos = 10*SIN_LOOK[ang];
// plot the pixel
Plot_Pixel((int)x_pos+x0, (int)y_pos+y0, color);
} // end for ang
Of course, look-up tables take up memory, but they are well worth it. "If you can precompute it, put it in a look-up table," that's my motto. How do you think DOOM, Quake, and my personal favorite, Half-Life, work? Assembly LanguageThe final optimization I want to talk about is assembly language. You've got the killer algorithm and good data structures, but you just want a little bit more. Handcrafted assembly language doesn't make code go 1,000 times faster like it did with 8/16-bit processors, but it can get you 2 – 10 times more speed, and that's definitely worth it. However, make sure to only convert sections of your game that need converting. Don't mess with the menu program, because that's a waste of time. Use a profiler or something to see where all of your game's CPU cycles are being eaten up (probably in the graphics sections), and then target those for assembly language. I suggest Vtune by Intel for profiling. In the old days (a few years ago), most compilers didn't have inline assemblers, and if they did, they sucked! Today, the inline assemblers that come with the compilers from Microsoft, Borland, and Watcom are just about as good as using a standalone assembler for small jobs that are a few dozen to a couple hundred lines. Therefore, I suggest using the inline assembler if you want to do any assembly language. Here's how you invoke the inline assembler when using Microsoft's VC++:
_asm
{
.. assembly language code here
} // end asm
The cool thing about the inline assembler is that it allows you to use variable names that have been defined by C/C++. For example, here's how you would write a 32-bit memory fill function using inline assembly language:
void qmemset(void *memory, int value, int num_quads)
{
// this function uses 32 bit assembly language based
// and the string instructions to fill a region of memory
_asm
{
CLD // clear the direction flag
MOV EDI, memory // move pointer into EDI
MOV ECX, num_quads // ECX hold loop count
MOV EAX, value // EAX hold value
REP STOSD // perform fill
} // end asm
} // end qmemset
To use the new function, all you would do is this: qmemset(&buffer, 25, 1000); And 1,000 quads would be filled with the value 25 starting at the address of buffer. NOTE If you're not using Microsoft VC++, take a look at your particular compiler's Help to see the exact syntax needed for inline assembly. In most cases, the changes are nothing more than an underscore here and there. |
|
|
Ajax Editor
JavaScript Editor