Best javascript editor debugger
Ajax website
Best javascript editor debugger
Ajax website
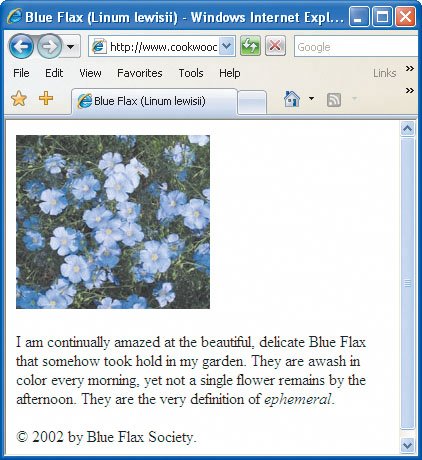
A Web Page's Text ContentThe text contained within elements is perhaps a Web page's most basic ingredient. If you've ever used a word processor, you've typed some text. Text in an (X)HTML page, however, has some important differences. First, (X)HTML collapses extra spaces or tabs into a single space and either converts returns and line feeds into a single space or ignores them altogether (Figures 1.10 and 1.11). Figure 1.10. The text content is basically anything outside of the markup. Note that each line happens to be separated with a carriage return. Also, I've used a special character reference © for the copyright symbol to ensure that it is properly displayed no matter how I save this document.
Figure 1.11. Note how the extra returns are ignored when the document is viewed with a Web browser and the character reference is replaced by the corresponding symbol (©).
Next, HTML used to be restricted to ASCII charactersbasically the letters of the English language, numerals, and a few of the most common symbols. Accented characters (common to many languages of Western Europe) and many everyday symbols had to be created with special character references like é (for é) or © (for ©). Nowadays, you have two options. Although you can still use character references, it's often easier to simply type most characters as they are and then encode your (X)HTML files in Unicode (and particularly with UTF-8). Because Unicode is a superset of ASCIIit's everything ASCII is, and a lot moreUnicode-encoded documents are compatible with existing browsers and editors. Browsers that don't understand Unicode will interpret the ASCII portion of the document properly, while browsers that do understand Unicode will display the non-ASCII portion as well. (For more details, see Chapter 21, Symbols and Non-English Characters.) The only symbol that you must not type in directly is the &. Since it has special meaning in (X)HTML, namely to begin those character references, it must always be expressed as & when used as text, as in AT&T. For more details, consult Adding Characters from Outside the Encoding on page 336. |
Best javascript editor debugger
Ajax website