Best javascript editor debugger
Ajax website
Best javascript editor debugger
Ajax website
About Character EncodingsWhen you type, a computer translates each character into bits. The system it uses for doing this is called a character encoding. The most basic character encoding is called ASCII and has 128 characters: the letters of the English alphabet, the numbers, and some common symbols. In non-English speaking countries, ASCII is clearly insufficient. Instead, they use slightly larger encodings sometimes encompassing more than one language. In order to maintain compatibility with English, these encodings treat the first 128 characters in the same way as ASCII and assign 128 new characters to positions 129256. The only problem is that each regional encoding does it in a different way. So, for example, if you want to write in Spanish, you might use the ISO-8859-1 encoding but if you want to write in Cyrillic, you need the ISO-8859-5 encoding. And if you want to write Spanish and Cyrillic together, or send a Spanish document to a Russian computer, it's a big problem. One rather cumbersome solution is to use character references to include characters in a document whose encoding otherwise wouldn't allow such characters. While this system continues to be used today (see page 336), it is perhaps most useful for largely English documents that contain a few foreign letters or unusual symbols, whose writers don't want to worry about the encoding. A more definitive solution is Unicode. Unicode is designed to be a universal system for encoding all of the characters in all of the world's languages. By assigning each character in each language a unique code, Unicode lets you include in a document any character from any language, and indeed multiple characters from multiple languages, without fear that it (or they) will be misinterpreted. Figure 21.1. Each of these characters has the same code (E4) in its respective local encoding, which makes it impossible, for example, to have both a Greek sigma and a Hebrew hay.
Figure 21.2. In Unicode, each character has a unique code, and thus they may all appear in the same document without confusion (as long as that document is encoded with a Unicode encoding such as UTF-8).
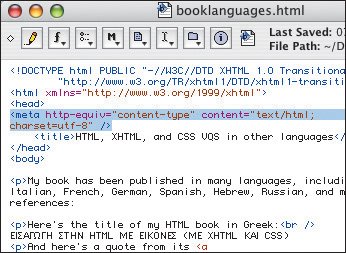
The form of Unicode most commonly used in HTML and XHTML is called UTF-8, which has the added advantage of encoding ASCII characters in the same way that ASCII does. This means that older browsers that may not recognize UTF-8 will still understand the English portion of the page, and indeed any character numbered 1128. Its principal disadvantage is that pages written in double-byte languages (like Chinese, Japanese, and Korean) take up about 1.5 times as much file space as they would with a local, more limited encoding. As a Web page designer, you must choose a proper encoding that encompasses all of the characters in your document, declare that encoding in the (X)HTML code (Figure 21.3), and specify the encoding when you save your file (Figure 21.4). If you've never specified an encoding before, your text editor selected one for youprobably the default encoding for your operating system. For example, most text editors on Windows in the U.S. will save "text-only" files in the Western ANSI encoding, whose official name is windows-1252. Figure 21.3. Here's part of an XHTML page that contains English, Greek, and Japanese. Since I'm going to save it in the utf-8 encoding, I declare that encoding with the meta tag (details on page 330).
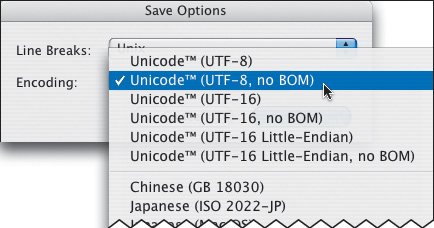
Figure 21.4. When I save the document, I am careful to choose the same encoding: utf-8, in this case. BBEdit as of version 7 automatically chooses the same encoding that you've declared. What a great feature!
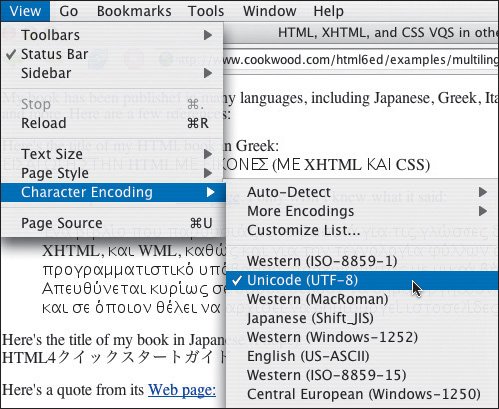
Once you've done your part, your visitors still need a browser that recognizes the encoding you've used as well as a font that includes the characters in your page (Figure 21.5). Most current browsers, including IE and Netscape/Firefox for both Mac and Windows from version 4 on, support UTF-8, as well as many regional encodings, although they sometimes require the installation of an additional language kit of some sort. You may want to suggest that your visitors go to Alan Wood's excellent Unicode Resources site (http://www.alanwood.net/unicode/) which includes information about getting the appropriate language kits and fonts, as well as the W3C's International section, which has a wealth of helpful information about writing multilingual Web sites (http://www.w3.org/International). Figure 21.5. When the visitor goes to this page, the browser sees the meta tag and automatically views the page with the proper encoding (utf-8).
|
Best javascript editor debugger
Ajax website