Source code editor
Website development
Source code editor
Website development
|
|
The View from the ServerAs clients grow thinner, servers get bigger. The world of e-commerce and Web-based archives has increased the need for big, fast, and reliable servers. Servers are expected to run constantly—24 hours a day and 7 days a week. Web servers hold medical records, bank records, library catalogs, and store catalogs. Servers provide education and entertainment content, and manage the business of sending data over the sprawling Internet. The following sections discuss some recent advances in the server industry, including
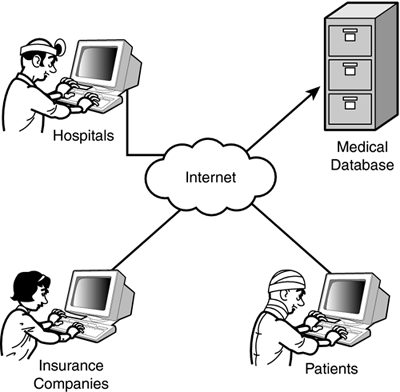
While vendors design servers to do these new things, they will also be building servers that do the old things better. Data TechnologiesIn the next few years, one of the most important areas for server development will be the management of data. The industry has swerved decisively in favor of the Web-based environment, and database scenarios that once would have called for a closed, proprietary solution now must be integrated with the Web. The medical records industry, for instance, is a natural application for Web and database integration. Medical records are logically housed at a central, secure, and reliable location. A medical professional might have need to access the medical records database anytime from anywhere in the world. Several companies are currently working on solutions that provide authenticated Web users with access to a central medical records database (see Figure 23.9). This technology could ultimately lead to better, more efficient, and more timely medical care. Figure 23.9. Accessing medical records over the Web.
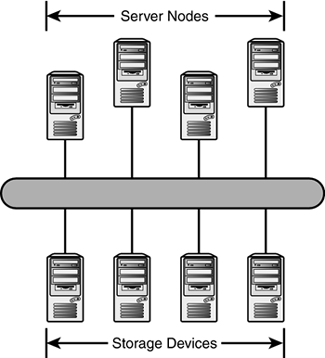
A large database requires a suitable database application (such as Oracle or MySQL), but it also requires lots of storage hardware. The data must reside in some retrievable form on a disk somewhere in the network. Hardware vendors are working on bigger, more efficient, and more reliable disk arrays for storing data, but a truly reliable system must also ensure that the path to the data remains open. In the traditional computing model, where a disk is attached to a single computer, the disk is accessible only when the computer is running. Innovations such as network file system (NFS) can make a single disk array accessible from multiple points. NFS developed within the Unix world but is now available for other networking environments. However, solutions such as NFS have management and performance limitations for high-volume and high-traffic data centers. A new concept called a storage area network (SAN) has recently emerged. The purpose of a SAN is to make the data as independent as possible from the systems that access the data. A SAN is actually a high-speed network of independent data storage devices linked to equal and independent server nodes (see Figure 23.10). The mesh of wiring interconnecting the storage devices and server nodes of a SAN is so thick and intricate that it is referred to as fabric. Several vendors (including IBM, Compaq, and Nortel) currently offer SAN products. SAN solutions are extremely expensive, but this technology is extremely valuable for large, mission-critical data centers. Figure 23.10. A SAN is a high-speed network of independent storage devices and server nodes.
Another data-related innovation that has received considerable attention recently is the Lightweight Directory Access Protocol (LDAP). LDAP is designed for fast lookups of directory-based data over a TCP/IP network. A typical LDAP scenario is an online directory in which you enter a user's name and receive a collection of additional parameters related to the user, such as home address, phone number, email address, and title. LDAP is a natural fit for many Web-based client/server applications, and vendors such as Netscape have been quick to add LDAP support to their Web server products. Many companies have developed their own homegrown LDAP applications to manage user data or even to support unified security on a diverse internal network. Novell NetWare has used a directory service for managing network resources since NetWare 4.0. The original NetWare directory was designed to use Directory Access Protocol (DAP) —a predecessor of LDAP—but NetWare now supports LDAP also. DAP and LDAP naming conventions are very similar. Microsoft realized that most of the information stored on its domain controllers (information about users, resources, and the structure of the network) was easily adapted to a directory-based organization and made LDAP the centerpiece for the Windows 2000 Active Directory environment. Network information on Active Directory networks is stored, read, and referenced through LDAP. You can even configure the Windows 2000 DNS server to store name resolution information in the LDAP-based Active Directory. Results of this noble experiment are still inconclusive. In the meantime, LDAP is currently a popular tool among developers and network admins for building homegrown directories and integrating them with scripts and applications. ClusteringRecent trends have brought more attention to the concept of using a bank of servers in parallel for a single function. The servers essentially share an identity. The client requesting the service does not know which server will perform the service. The client might not even know that the cluster exists. Requests are distributed invisibly among the members (called the nodes) of the cluster. A cluster is really a group of computers that appears to the outside world as a single computer. The advantages of a cluster are
Server clusters are often used for critical network functions. You'll find server clusters acting as proxy servers or DNS servers. Clusters are also used for extremely complex calculations. The National Science Foundation gravity wave detector project, for instance, uses a cluster of 100 Linux computers to process data from gravity wave detectors. Several clustering products are available for Unix and Linux operating systems. The Beowulf clustering package is a popular option for Linux clusters. Microsoft provides clustering services through the Microsoft Cluster Server product. A version of Cluster Server is included with the Advanced and Data Center versions of Windows 2000 Server. The Microsoft clustering services do not provide the full range of parallel processing capability offered with some cluster software. Some OS vendors (such as Sun Microsystems) are reportedly working on technology that will remove even more of the identity of individual servers within the cluster. The cluster will not be assigned to a single task but will function as a single logical server for all purposes. Java-based applications will not be loaded onto a single server but will instead be managed by the cluster itself; the cluster management software will dynamically control how and where a task is executed. Server BoxesThe principles of TCO apply to servers as well as clients. Even as some servers grow bigger and faster, others are growing smaller and simpler. Some of the roles once performed by servers are now being assigned to small boxes. The server box does not offer the range of capabilities possible with a real computer, but it is designed to perform a single task with very little configuration. Because a server box has no monitor, it is often configured through a Web interface. The server box has enough of a built-in Web server to provide Web access to a user working from a browser somewhere on the network. Server boxes currently act as various combinations of the following:
The simplicity of a dedicated device makes the server box a useful option for small networks with light network traffic and no professional network administrators on hand. |
|
|
Source code editor
Website development