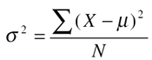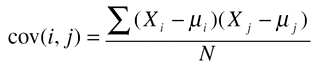Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
MethodologySo, specifically how do game AI developers proceed when refining the problem and trying to understand the data? Basically, there's wisdom, experimentation, and analysis! Expert FeaturesEssentially, as AI engineers, we can have an effect on both the size of the problem and its complexity. We can do this primarily by selecting the right features as inputs to the problem. A good place to start for finding features is to use the case studies, and combine the inputs to more relevant problem variables:
These are often called expert features because the engineers use their knowledge of the problem to extract meaningful information for the AI. The outputs also can be defined as higher-level actions to further simplify the problem. Identifying Features EmpiricallyAs programmers, we generally have a good feel for solving problems. We can identify important points and exploit them. AI engineers use a similar methodology. They use their experience to identify the relevant data and put it to use. Essentially, wisdom is used to assign preliminary priorities to the features. Then they can be ordered by importance. Correcting these estimates is a matter of experimentation by trying out lots of different examples with different features. There are two methodologies to find good features:
The incremental approach is used for obstacle avoidance; one front whisker is used by default, but side whiskers are added to provide guidance when turning. The decremental approach is used for target selection; three angles and three distances are the inputs at first, but only the last three are reliable features. With a bit of experience, the first set of chosen features can become quite accurate. Then, if it works, the model can be simplified. If it doesn't work, more features can be added until the problem is solvable. There is no algorithmic solution, so expert design and testing is unavoidable. Other automated solutions will most likely follow this approach (for instance, using genetic algorithms). Data AnalysisExperimentation relies on the intuition of the AI engineer. Understanding the problem in practical terms can become a formal process thanks to data analysis. This topic in itself deserves more than a subsection, but these few hints should be enough to get us started. In classical game development, it's quite rare that statistical analysis is necessary; A* pathfinding and finite-state machines certainly don't need it! With techniques based on learning, however, this is very important. As AI becomes more complex, the chances of getting the model right will diminish drastically when only experimentation is used. Data analysis does incur a certain time investment (overhead), notably to gather the data (or even to get comfortable with the analysis tools). However, the insights provided by statistics more than make up for lost time, and can even improve the quality of the behaviors. Reliable adaptation is arguably only possible with these methods. The Right ToolsMany packages, both commercial and freely available, can perform statistical analysis. These include Mathlab, GnuPlot, Mathematica, and Excel. It can take a while to get comfortable with these, but most of them are easy to use for simple tasks. These tools provide ways to manipulate data, as well as visualize it. We need both these operations to extract trends out of the data. Let's cover visualization and then basic manipulation with statistics. Visualizing DataMost data samples are multidimensional. When there are only two parameters, it's easy to visualize the values using a 2D plot. We can easily extract trends from this data by looking for patterns; X/Y scatter plots, line graphs, box-whisker diagrams, bar charts, and histograms are all good choices. Chapter 20, "Selecting the Target," did this to analyze the effectiveness of the target selection, plotting the hit ratio in terms of the distance. With three dimensions, data is already much harder to observe. Some visualization tools can handle arbitrary dimensions (for instance, self-organizing feature maps). Such techniques work by organizing the data into groups that can be visualized in 2D. Patterns become obvious with this approach, but it's harder to understand where the patterns are! The alternative is to manually select pairs of parameters, and plot them together using 2D techniques. Sadly, this only reveals "first-order" patterns. Projections can also be used to convert n variables into one dimension (to reduce the dimensionality by combining parameters). The projections take the shape of user-defined equations that take n parameters and produce one result. Projections can be difficult to understand, but provide a viable solution to visualize multidimensional data. Relevant MetricsWhen trying to understand data, it often helps to extract relevant information from the data. Various statistical metrics can provide great assistance. The mean m (Greek mu) is the sum off all the data samples X divided by the number of samples. The median is the data sample right in the middle of the sorted array. It's also useful to find percentiles; for example, the first quartile is the sample 25 percent of the way through the sorted data, and the third quartile is at 75 percent. These metrics describe the body of the data, so we can understand which part of parameter space it occupies. The variance (denoted s2) is a measure of the spread of the data. It is computed using the sum of square distances of each sample X to the mean, divided by the number of samples N:
Most statistical packages provide this equation. The more commonly used standard deviation s is computed by the square root of the variance. Covariance measures the amount of correlation between two random variables. This enables us to identify dependencies between parameters of the problem (and potentially causal links). Covariance is computed much like variance, but using two parameters, i and j, for each sample X:
This really brief crash course in statistics should be enough for most game AI developers. See [Weisstein03] or [Kachigan91] for more information. |
|
|
Ajax Editor
JavaScript Editor