 Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Defining Reinforcement TheoryFor reinforcement learning to be necessary, the problem needs to be modeled in a particular way, although only the concept of reward differs from supervised learning techniques. In-Game SituationLet's assume the animat is on the top floor of a level, and has the opportunity to throw a grenade down to the lower levels. There are three different gaps to drop the grenade, each leading to an explosion in a different room. Other players frequently traverse the three rooms. The traffic in the rooms varies from one second to another, but the statistics show there is a regular trend over time. So, at each point in time a constant probability is that one player will be present. Sadly, as visibility is occluded, there is no way to check how many people are in each room at any moment. In addition, the animat has no experience or inside knowledge about the terrain, so it doesn't know about player traffic and the probabilities of rooms being occupied. The only way to check is to actually throw a grenade and listen for cries of pain! If the animat has only one grenade, a random throw is the best thing it can do; at any time, it's arbitrary whether the room is occupied. If multiple grenades are available, however, the animat can learn to perform better over a period of time—specifically, attempt to cause as much third-party damage as possible. Therefore, the problem is to determine the best place to throw the grenade (that is, find the room with the highest traffic) to maximize long-term damage. Reinforcement ModelThis particular game scenario is one of many examples of a reinforcement problem. There is only one situation and a set of actions available to the animat. After an action has been executed, the environment immediately returns feedback about the result in the form of a scalar number. The general architecture of RL can be adapted to other problems, as shown in Figure 46.1. Specifically, any situation in which a reward is given for particular actions is classified as an RL problem. This includes an animat learning actions according to a designer's wishes. Figure 46.1. On the left, a typical model of the interaction between the agent and the environment. On the right, an embodied agent that uses a reward function created by the engineer.
States and ActionsIn the grenade-throwing example, there is only one situation: "The animat is on the top floor with a grenade." Often, there are many more situations in a world. Each of these is known as a state. For each state, a set of actions is available to the agent. In the example, the actions were described as follows:
Naturally, in theory, there can be an arbitrary number of actions in each state. In game situations, however, we can expect there to be a reasonable number of actions in each state. Reward SignalAfter each action has been executed, the environment returns feedback immediately. This feedback takes the form of a scalar number, which can be understood as an evaluation of the action—hence the term evaluative feedback. The reward at time t is denoted rt (both real numbers). Intuitively, a beneficial action has positive feedback, whereas a poor action has negative feedback. The range of the feedback value is in fact not important for the learning algorithms, as long as it can express the various levels of performance. In our grenade example, the feedback could depend on the number of other players injured. If no players are hit, the feedback is 0 (not negative in this case). The feedback from the environment is also known as reward signal. The allusion to a signal implies that it can be monitored over time, as shown in Figure 46.2. Such graphs are found relatively often in RL, because with a quick glance they reveal the performance of an agent. Figure 46.2. Graph of the reward values obtained over time. The return (accumulated reward) is superimposed.
In some cases, the reward associated with an action may not be immediate. This is called delayed reward—obviously! As long sequences of actions can lead to a goal, delayed reward is an important concept for most RL algorithms. The algorithms need to associate delayed reward with actions that lead to an immediate reward. Behavior PolicyThe purpose of learning is to find a good policy. A policy expresses what action should be taken in each state (such as where to throw the grenades). Because it's defined for every state, the policy is essentially a representation of the agent's behavior. A policy is denoted p (Greek pi). A stochastic policy provides the probability of selecting an action in a given state. Formally, it's a function mapping each state/action pair onto a probability p in the range [0,1]. Noting that S = {s0,s1K sn} is the set of all states, and A = {a0,a1K am} is the set of actions, we have the following:
This definition expresses the policy p mapping the states and actions onto a unit range, for all (| Stochastic polices can be very useful as behaviors, but especially during learning. (For instance, it keeps track of the probabilities explicitly.) In some cases, however, a deterministic policy is more useful, notably when only the best action is needed for each state (and not the entire probability distribution).
Generally, more than one policy is suitable for an animat within a game. However, one policy is defined as the target for learning. This is the optimal policy, written as p*. The asterisk used as a superscript indicates optimality in RL theory. Defining OptimalityBecause a wide variety of problems can be modeled using RL, different kinds of results may be required, too. The final performance of the policy and learning speed are both desirable criteria in computer games. Let's look into the most common metrics for judging RL algorithms [Kaelbling96]. Optimal ReturnTo measure the performance of an agent over time, it's necessary to introduce the concept of return. The return is generally an accumulation of the reward signal over time. The agent's responsibility is to maximize the expected return at time t, denoted Rt. There are three principal ways to define the return, each leading to different behaviors.
The major disadvantage with average rewards is that no sense of time is included. A potential reward far in the future is just as important as the next one. The discounted reward is preferred instead. Learning and PerformanceConvergence is defined as reaching the optimal policy after a certain number of iterations (just as with optimization algorithms covered in Chapter 17, "Perceptrons"). Different properties of the convergence are used to measure the performance of learning algorithms:
It's often practical to visualize the convergence. We can do this by plotting the reward as a function of time in a graph. Generally, nonplayer characters (NPCs) in games need to learn both fast and accurately. Markov Decision ProcessesMost reinforcement learning problems class as Markov decision processes. In a Markov decision process, two additional concepts are defined; the probability of an action succeeding, and the expected reward. Assuming action a is taken from state s, the probability s' being the next state is written as Both P and R are considered as the world model, because they define the environment and its typical reaction. There are two categories of RL problems: those where the world model is known, and those where it is not. Note There is a common background between finite-state machines and RL theory. In Chapter 40, "Nondeterministic State Machines," we studied probabilistic finite-state automata, with probabilities associated to each transition; these are classed as Markov chains. Probabilistic finite-state machines define probabilities for each output, and are considered as hidden Markov models. In RL problems, we have reward signals rather than outputs; they fall into the category of Markov decision processes. |
|
|
Ajax Editor
JavaScript Editor



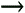 (
(

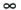 denotes infinity). To limit the computation, a
denotes infinity). To limit the computation, a 
