 Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Fundamental ElementsEach of the RL algorithms defined in the following sections relies on common insights to provide solutions. Value FunctionsAll the techniques presented in this chapter—and most in RL—are based on the concept of value functions. Essentially, a value function is an estimate of the benefit of a situation. In practice, there are value functions defined for states, and for actions given a specific state, as shown in Figure 46.3. This allows RL algorithms to any reward signals to learn the policy, whether delayed or not [Sutton97]. Figure 46.3. State values and action values drawn within the world model. Some transitions are probabilistic, denoted by dotted lines. The double circle represents a state where a reward of 10 is collected.
State ValuesState values are an indication of how good it is to be in a certain state. (For instance, this bridge has a low value; it must be unsafe.) These values are generally defined as the expected return if the policy is followed from this state onward. The value of state s for policy p is written Vp(s). Formally, it's defined as follows:
Remember that Rt is the expected return, usually defined as a discounted reward. Ep is the estimate of this return value starting given s as a start state at time t. Action ValuesLikewise, action values indicate the benefit of taking an action in a current state. (For instance, using an axe on a tank has low benefit.) These correspond to the expected return by following the policy p after taking action a from state s. The action value is also known as a Q value, and written Qp (s,a). Formally speaking:
Because there are many actions per state, the action values require more storage than state values. Using Q values estimates the benefit of actions separately, whereas everything is considered together with state values. Recursive DefinitionOne of the problems with the previous equations is that there's no obvious way of computing the estimated return Ep. This is the task of the various learning algorithms. However, the definition of state/action values can be reformulated to expose a recursive definition. This recursive property is exploited by most of the RL algorithms to compute the policies. The intuition is that neighboring states also contain state/action values, so we can define a relationship between a state value and its neighbor's estimated return. Using the transition probabilities and the expected reward, we can express the estimated return of a state. Assuming a discounted reward with coefficient g, the following holds (see Listing 46.1):
Intuitively, the state value is the average of the discounted neighboring state values, including the reward collected by taking the action. The pseudo-code snippet in Listing 46.1 explains the equation in more practical terms. Listing 46.1 Direct Application of the Preceding Equation, Which Can Be Used to Compute State Values
There could be an RL algorithm based on this equation. However, there are a few small details to be resolved—notably how to keep track of the various estimates. Optimal Value FunctionsThe purpose of the learning is to find the optimal policy p*, which acquires the most return over time. We've discussed this already, but now we can associate optimal value functions with it [Sutton97]. A policy p is better than another p' if and only if (
We can also express the optimal state value as the maximal value, for all states:
Similar equations can define the optimal state/action value for each state/action pair, denoted Q*(s,a). These values are targets for all of the learning algorithms described. Types of Reinforcement ProblemsReinforcement problems form a broad category. The can generally be classified into subproblems (for instance, episodic and incremental). In many cases, we can convert our problem to either of these options, depending on the preferences of the algorithm:
In game development, it's generally appropriate to use incremental learning within the game (online), and episodic problems during the development (offline). Exploration Versus ExploitationReinforcement problems present a perfect example of a fundamental problem to learning AI. When do we assume we've learned enough, and start using what we've learned? Two different strategies are in opposition, as shown in Figure 46.4: Figure 46.4. The behavior policy in a 2D grid, where the actions lead to the top left. Double arrows denote exploration moves that diverge from the learned behavior.
Often, these two strategies are combined into policies that are used during the learning. For example, e-greedy (pronounced "epsilon greedy") policies use the best-known action, but make a random choice with a probability of e. This is a special case an e-soft policy, where the probability of each action p(a,s) is at least e divided by the number of actions in this state | A(s) |:
The concept of exploration and exploitation enables us to identify two types of learning algorithms: those that depend on the policy chosen to learn the optimal policy, and those that don't. These are known as on- and off-policy algorithms respectively:
In brief, the policies chosen are influent factors for the quality of the learning as well as the final behavior. Learning ToolsThe algorithms presented in the next section make use of similar techniques, as well as the common definitions already provided. BootstrappingBootstrapping is the process of updating an estimate based on another estimate. This can prove useful during learning because it can improve the quality of the estimates over time. In RL, bootstrapping can be used to optimize the state values. Intuitively, it's possible to estimate how good a state is based on how good we think the next state is. In contrast, nonbootstrapping techniques learn each state/value separately, without using estimates of neighbor states. Both approaches have been shown to have their own set of advantages, and there are numerous algorithms based on either (for instance, temporal-difference learning). BackupBackup is the process of using future return to estimate the expected return of the current state. So the return is percolated backward from any point st+h in the future toward state st we want to evaluate. The backup process can be seen as a treelike structure, spanning out from the current state [Sutton97]. This tree has different properties, as shown in Figure 46.5: Figure 46.5. A tree of possible states starting from the current state. A full backup uses the state values of all the children, and a sample backup only checks one child branch.
The backing-up process usually works from one state value to another. However, this can also apply to action values, too. |
|
|
Ajax Editor
JavaScript Editor


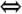 ) the corresponding state values are above or equal, for each state
) the corresponding state values are above or equal, for each state 


