Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
Representation of Decision TreesBefore looking into what a DT can do, or even how we can build one, we need to understand the basic concepts behind the data structure. A DT outputs a prediction based on some input attributes. There are two different kinds of DTs: classification and regression trees. There are no differences in the types of inputs; both can take continuous or symbolic values. It's the output that determines the type of tree. A DT with continuous outputs is known as a regression tree, and classification trees output categorical values instead—as summarized in Table 26.1.
The first subsection explains data samples and their relevance. These are processed by DTs and often serve as the input/output format, too. Then we investigate the representation of the tree, revealing what makes them so simple and fast. Finally, the important parts of the tree—such as the decision nodes and leaves—are examined further. Data SamplesData is a fundamental requirement of pattern recognition, and even machine learning generally. Data is often expressed as individual samples—also known as cases, instances, patterns, and, no doubt, many other things. Essentially, a data sample is a set of attributes, a.k.a. predictor variables. Each attribute can be a continuous value (that is, floating-point number) or a symbol (that is, unordered discrete values). These attributes can represent just about anything conceptually; in the context of weapons, properties such as weight, firing rate, and maximum ammo would be attributes. There is an additional attribute with a special meaning, known as a response variable (or dependent variable). It can be a symbol representing discrete categories (for classification) or a continuous value (for regression). This is the criteria for making decisions on each of the samples for both classification and regression problems. Table 26.2 shows the problem of predicting the total damage inflicted based on the properties of the weapon. Damage is used as the response variable, so the others are predictor variables. Weight and type are categorical, whereas the rest are continuous.
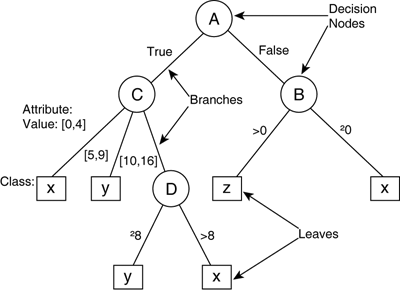
There is no difference between the predictor and response variables; almost any attribute can be a response. The variable used as a basis for the classification process will be chosen depending on each problem. To classify weapon types, for example, we could choose the attribute for damage or capacity (among others). Note Data samples are commonly used throughout the fields of AI, including for other techniques that can be used for pattern recognition and prediction. This notably includes neural networks. We sidestepped the problem of classification during Chapter 17, "Perceptrons," and Chapter 19, "Multilayer Perceptrons," (focusing mostly on function approximation), but a majority of the concepts throughout this chapter can be applied directly to neural networks. Decision TreeA DT is basically a tree, in the standard computer science meaning of the word. The data structure is formed of nodes joined together by branches (see Figure 26.1). These branches are not allowed to form cycles, or the tree would become a graph (difficult to use for decision making). Figure 26.1. A simple DT with the root node at the top, and each decision node as a circle. The leaves are represented as boxes.
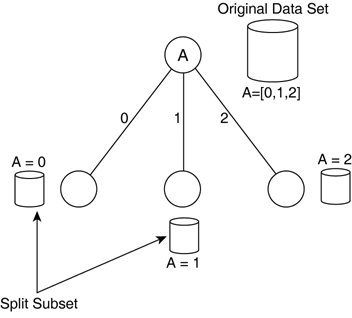
One special node is known as the root. This is conceptually the base of the tree, and it's possible to traverse the tree from any node to the root. Another particular kind of node forms the end of each branch: leaf nodes. This is a very broad description of a tree data structure. Anyone with reasonable experience of programming languages should be familiar with this. However, for DTs in AI, there are particular meanings associated with each of these concepts. Each level in the tree can be considered as a decision; a node is a conditional test, and each branch is one of the possible options. More formally, the nodes contain a selection criterion, and the branches express the mutually exclusive results of the test. Fundamentally, each conditional test sorts the data samples so that each corresponds to only one branch. If we consider all the samples as one large data set, the decisions split this set into distinct subsets—as depicted in Figure 26.2. Combining these tests into a hierarchy actually splits the data into even smaller parts until the leaf is reached. Each leaf corresponds to a small but exclusive part of the initial set. Figure 26.2. Splitting the DT into mutually exclusive subsets using the decision nodes.
Conditional TestsNaturally, there are many possible ways to represent the decisions. These depend on the type of the attribute as well as the operation used in the conditional test. Because the attributes can be symbols and continuous values, the tests can be Boolean conditions as well as continuous relations. The number of possible results to the test corresponds to the number of branches starting at this node. Common conditional tests include the following:
Typically, a unique conditional test over only one attribute is used (for instance, B==true). This often suffices because decisions can be combined hierarchically in the tree to form more complex decisions. As an extension to DT, however, some conditional tests involve more attributes (for instance, testing A==1 and B<0), which can improve the accuracy of the tests—at the cost of simplicity. In this case, there are more combinations of possible results, so there are more branches. See Table 26.3.
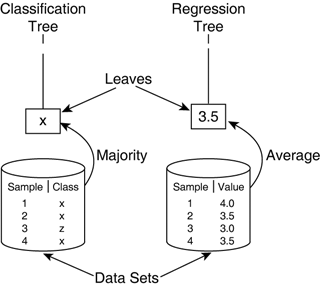
Generally, more predictor variables used in a test imply more branches. However, it's possible to use an arbitrary number of attributes and map them to a single Boolean decision. This would require evaluating expressions such as (A and B) or C. Similar equations can be used to convert continuous values to a single number. The problem with such complex expressions is that they are harder to learn! Leaves and Response VariablesThere is a single response variable associated with leaves of the tree only. These response values also can be either discrete or continuous. Each of the leaves corresponds to a particular subset of the data samples (see Figure 26.3). For classification trees, the response variable matches the estimated category for all the samples in this leaf. On the other hand, in regression trees, continuous response variables generally indicate the average of all the samples corresponding to the leaf. Figure 26.3. The value stored in each leaf corresponds to the response variables of the samples.
The type of response variable does not affect the structure of the tree, although a different data type container is needed in the leaves—obviously! There are also key differences in the way the tree is built, but we'll get to that after we know how to use it. |
|
|
Ajax Editor
JavaScript Editor
 0
0