Free JavaScript Editor
Ajax Editor
Free JavaScript Editor
Ajax Editor
|
|
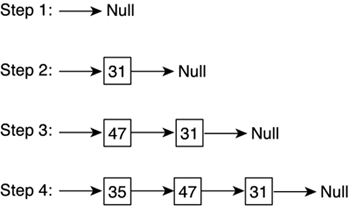
The Standard Template LibraryHaving a deep knowledge of all the fundamental data structures and algorithms is key to becoming a successful game programmer. However, coding these structures each time you need them is prone to introduce errors, and thus is a risky process. Let's face it, most game programmers could not write a linked list from scratch and get the code right on the first attempt. Two solutions have been proposed. Some companies have developed in-house code bases that encapsulate many fundamental and sophisticated classes. These classes are built through the years, and thus are stable, well-tested frameworks from which a game can be derived. An alternative is to use a ready, standard set of classes that provide good performance and are rock solid. This is precisely what the Standard Template Library (STL) is all about. The STL was introduced in the 1990s as a collection of classes that made OOP easier. It includes lists, queues, hash tables, and many other exotic structures and their access methods. You can trust the STL's code to be error-free because it is used daily by thousands of programmers worldwide. Any error gets fixed quickly, so you can trust the code base to be stable. Moreover, the STL is very efficient. The fastest access algorithms are built into the system, so you can trust the library. In addition, the STL provides flexibility. All classes are built using templates, so you get all the benefits of generic programming. You get generic lists that you can adapt to any element, so the code size also diminishes. For those not familiar with generic programming, it is a C++ mechanism that allows a class to be parameterized. You can define a generic list, which accepts as a parameter its base type, so the same list can hold a series of integers or a series of complex structures. Another advantage of the STL is coherence. Most data structures are accessed in a similar way, which makes programming more abstract because you don't need to know all the implementation details of the different classes. The access method is usually implemented via iterators, which provide a convenient way to scan the structures. Use of the STL spread rapidly in the mainstream application development segment. Databases, word processors, and so on take advantage of it frequently. In game development, however, it suffered the "Not Coded Here" syndrome. Developers are rarely enthusiastic about using anyone's code but their own, so the loss of fine-grained control that the STL implies was not very welcome in the beginning. But this reminds us of the old days when C++ was rejected because it was slow, or even earlier, when anything not-assembly was considered a sin. Game developers naturally care a lot about performance and control, and thus introducing any technology takes some time. Luckily, more and more game developers today are embracing the STL as a core technology, and we see less and less developer time being devoted to coding the ever-present linked list or binary tree. To make life even easier, today the STL is built into many standard compilers such as Microsoft's Visual C++ or Borland's C. Besides, many free implementations of the STL exist (made by companies like Hewlett-Packard or Silicon Graphics). Now I will provide an overview of the STL structures and philosophy. For the rest of the book, I will combine the STL with non-STL code, so you can gain complete understanding of the different alternatives available. ContainersThe STL includes many container classes, which are where user data is generally stored. These containers are all templates, so you can adapt them to any type of data. The containers provided by the STL are vector, list, deque, set, multiset, map, multimap, hash_set, hash_multiset, hash_map, and hash_multimap. VectorA vector is a sequence that allows random access to elements: O(1) insertion and deletion of elements at the end of the vector and O(number of elements) insertion and removal of any other element. Vectors can be dynamically resized, and memory management is automatic, so you don't have to call malloc. Here is a simple integer vector example: vector<int> v(3); v[0]=0; v[1]=1; v[2]=2; v.insert(v.begin(), 5); This code produces a vector such as: v[0]=5; v[1]=0; v[2]=1; v[3]=2; Note how the insert routine effectively resizes the vector, hiding all memory management details from the user. Vectors have dozens of access functions, which perform tasks such as sorting, reversing order, searching data, and so on. ListAn STL list is a doubly-linked list, so it supports bidirectional traversal and constant-time insertion and removal (that is, once we are at the insertion point). Here is a simple list in action: list<int> l; l.push_back(31); l.push_front(47); l.insert(l.begin(),35); In Figure 3.15, you can see a diagram of the list and its contents after this sequence is executed. Figure 3.15. STL list example.
DequeA deque is useful for implementing both queues and stacks. It provides constant-time insertion and removal from both the beginning and end as well as linear time insertion and removal for elements in-between. A deque used as a stack will insert and remove elements from the same end of the structure (be it the beginning or the end), whereas a deque used as a queue will perform both operations on opposite ends of the sequence. Here are two code samples. The first uses a deque to implement a stack, the second a queue:
deque<int> s;
s.push_back(1);
s.push_back(2);
s.push_back(3);
s.push_back(4);
s.push_back(5);
while (!s.empty())
{
printf("%d\n",s.back());
s.pop_back();
}
This code sequence produces the following output: 5 4 3 2 1 The following code is a queue example. Notice how we only need to make minimal changes to the preceding code:
deque<int> q;
q.push_back(1);
q.push_back(2);
q.push_back(3);
q.push_back(4);
q.push_back(5);
while (!q.empty())
{
printf("%d\n",q.front());
q.pop_front();
}
The output will reflect the FIFO behavior we expect from a queue: 1 2 3 4 5 Sets and MultisetsSets and multisets are sorted, associative containers. These data structures are basically sequential in nature, so they hold a series of similarly typed data. We can have an associative container of integers, character strings, and so on. The main difference between sequential structures (lists, vectors, deques) and sets is that sequences are optimized for access (insertion, removal, and so on), whereas sets are optimized for logical operations. In a set, you can perform a query like, "Which names on set A are also on set B?" efficiently. This query is usually performed by keeping the elements ordered, so inserting elements in the set cannot be performed in a random way. Both sets and multisets are simple in nature. This means that the element they contain is also the key value for a search or logical comparison. You can have a set of strings, but you cannot have a set of structures each with a string as key. More complex containers are required for that. The difference between a set and a multiset is simply that sets only allow an element to appear once in the set, whereas multisets allow different elements in the same set to be identical. Sets and multisets are usually accessed with the functions set_union, set_intersection, set_difference, and set_includes. The first three functions are really straightforward:
The function includes is a search method that scans the incoming set to try to find a specific element. Map and MultimapA map/multimap is a generalization of sets especially designed to model relationships between pairs. A map contains a set of key values and a set of generic data values, which the key values are coupled with in a one-to-one relationship. As an example, here is an STL map:
struct ltstr
{
bool operator()(const char *s1, const char *s2) const
{
return strcmp(s1,s2)<0;
}
};
map <const char *,int, ltstr> ages;
ages[Daniel]=45;
ages[Alex]=12;
ages[Cecilia]=32;
Here we are storing a group of people along with their associated ages. As with regular sets, we can perform logic operations and searches on maps, which are optimized for this purpose. We can also traverse the structure using iterators to list the elements it contains. Hash_set, Hash_multiset, Hash_map, and Hash_multimapSets and maps are implemented in a way optimal for logical operations and ordered traversal. Elements in the structure are permanently kept in ascending order so most access operations are logarithmic in cost. But for random access to data (by key value), using hash tables can provide a speed boost. In many cases a hash table provides quasi-constant access time to data held within. Thus, a hashed variant of all associative containers is provided by the STL. Although different implementations of the STL might offer slightly different behaviors, hashed versions of sets and maps are generally more efficient if you plan to access the data in a random way, directly by seeking by key value. Under this access mode, a hash table provides faster access than a linear structure. But if you plan to list the elements and thus traverse the ordered structure, the regular sets and maps are recommended because they provide sequential access. This consideration is especially important for larger structures, where a small speed improvement might in the end provide a significant time savings. Again, the difference between a map and a multimap is simply that maps need each element to be unique (in key value). Multimaps are less restrictive and allow multiple identical keys to coexist. IteratorsAn STL iterator is a generalization of a pointer. Iterators provide a clean, memory-safe method of traversing STL data structures. For example, if you need to print all the elements in a vector, you can do it by using an iterator:
vector<int> v(3);
v[0]=0;
v[1]=1;
v[2]=2;
vector<int>::iterator pos=v.begin();
while (pos!=v.end())
{
printf("%s",(*pos));
pos.next();
}
Iterators have the added advantage over pointers of being type generic. An STL iterator can be used on most of the STL's data structures, and most STL algorithms (sorting, searching, and so on) are designed to work with iterators. Also, memory access using iterators is protected, so you can't move past the end of a list and so on, further helping to reduce errors in code. |
|
|
Ajax Editor
JavaScript Editor